Voice Gets More Real-Time
Today’s digest spans holistic video dubbing, streaming speech LLMs, expressive and waveform-native TTS, and low-latency voice conversion. The common thread: better control, faster inference, and more natural-sounding speech across generation and recognition.
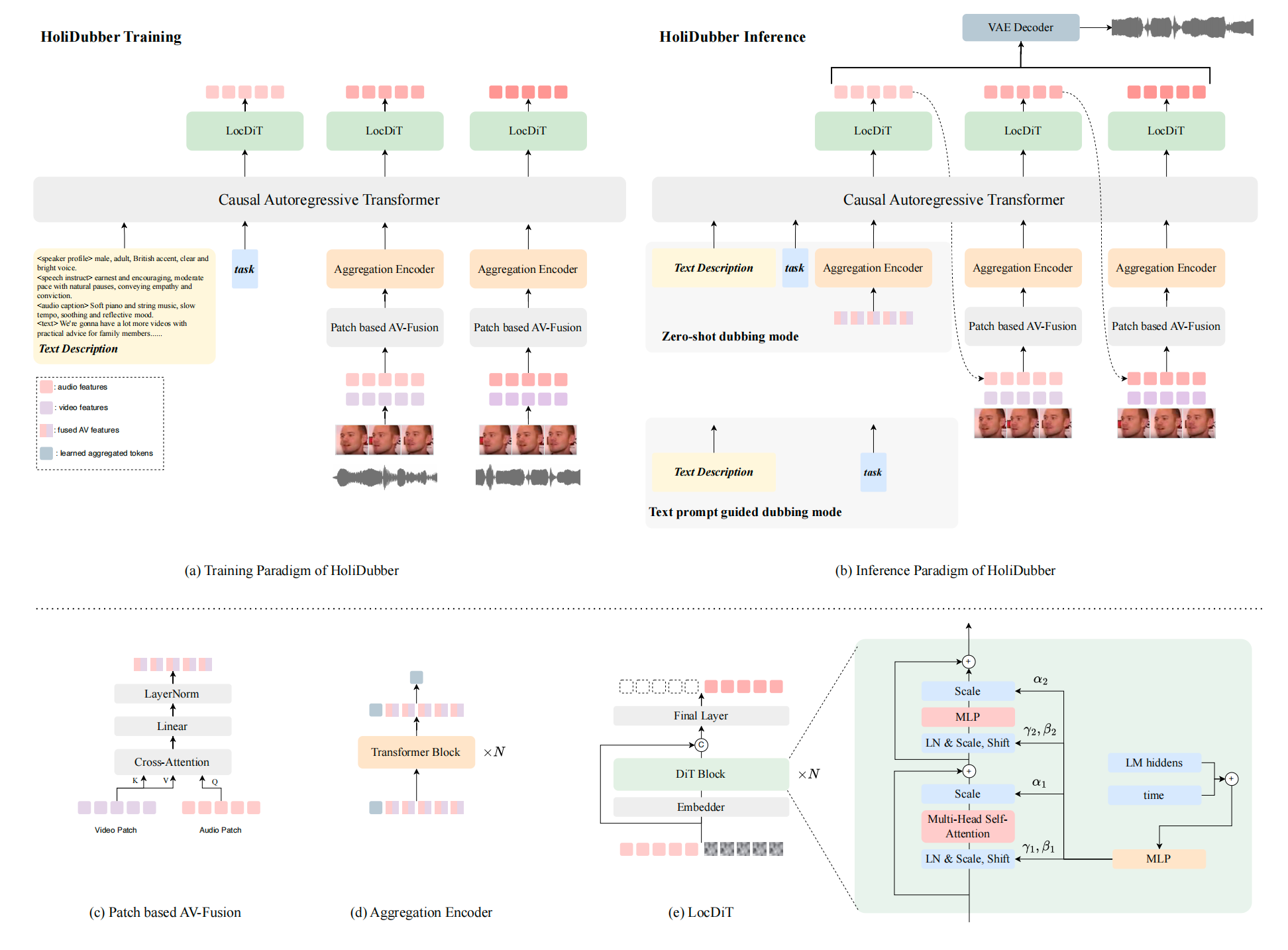
HoliDubber overall framework diagram. From HoliDubber.
Video Dubbing & Visual Speech Alignment
SpeechLLMs & Streaming Recognition
TTS & Expressive Voice Synthesis
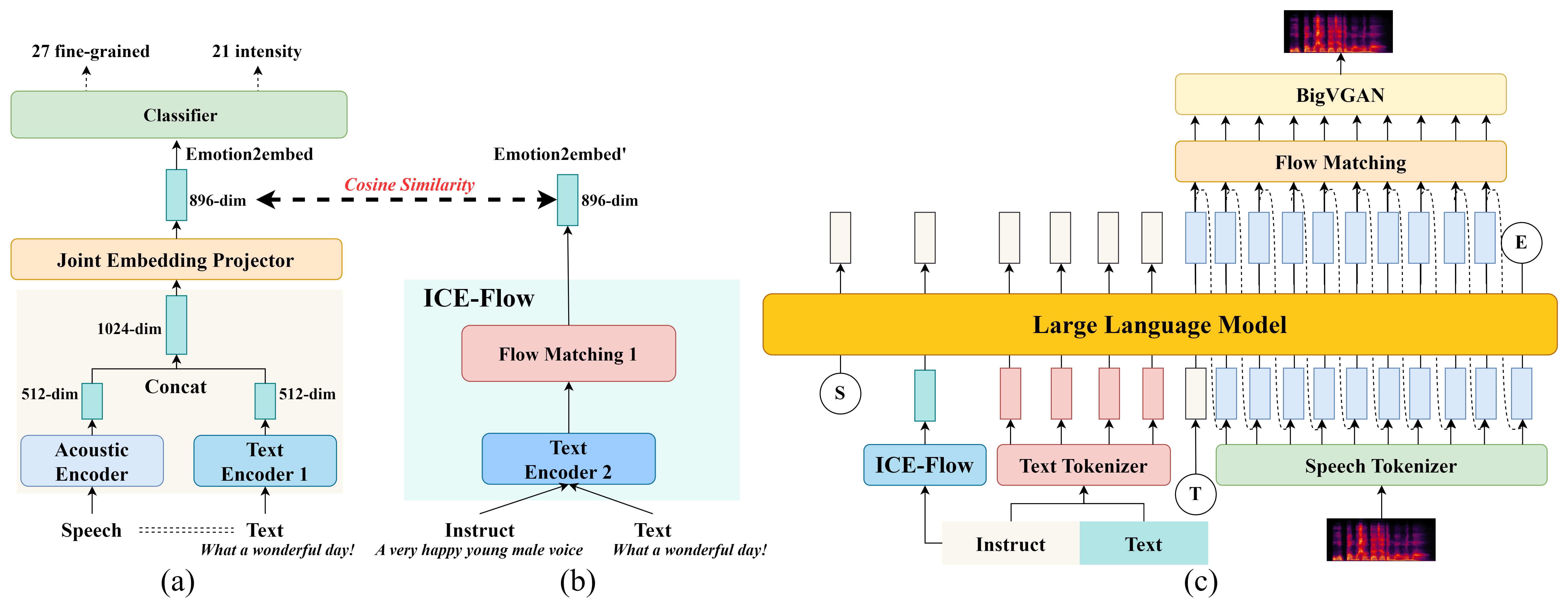
EmoInstruct-TTS
EmoInstruct-TTS: Dual-Path Instruction-Guided Emotional Speech Synthesis
EmoInstruct-TTS is a dual-path emotional TTS system that separates semantic planning from fine-grained emotion control using natural language instructions and a rich emotion embedding. This approach improves emotion accuracy and speech naturalness beyond prior instruction-based systems.
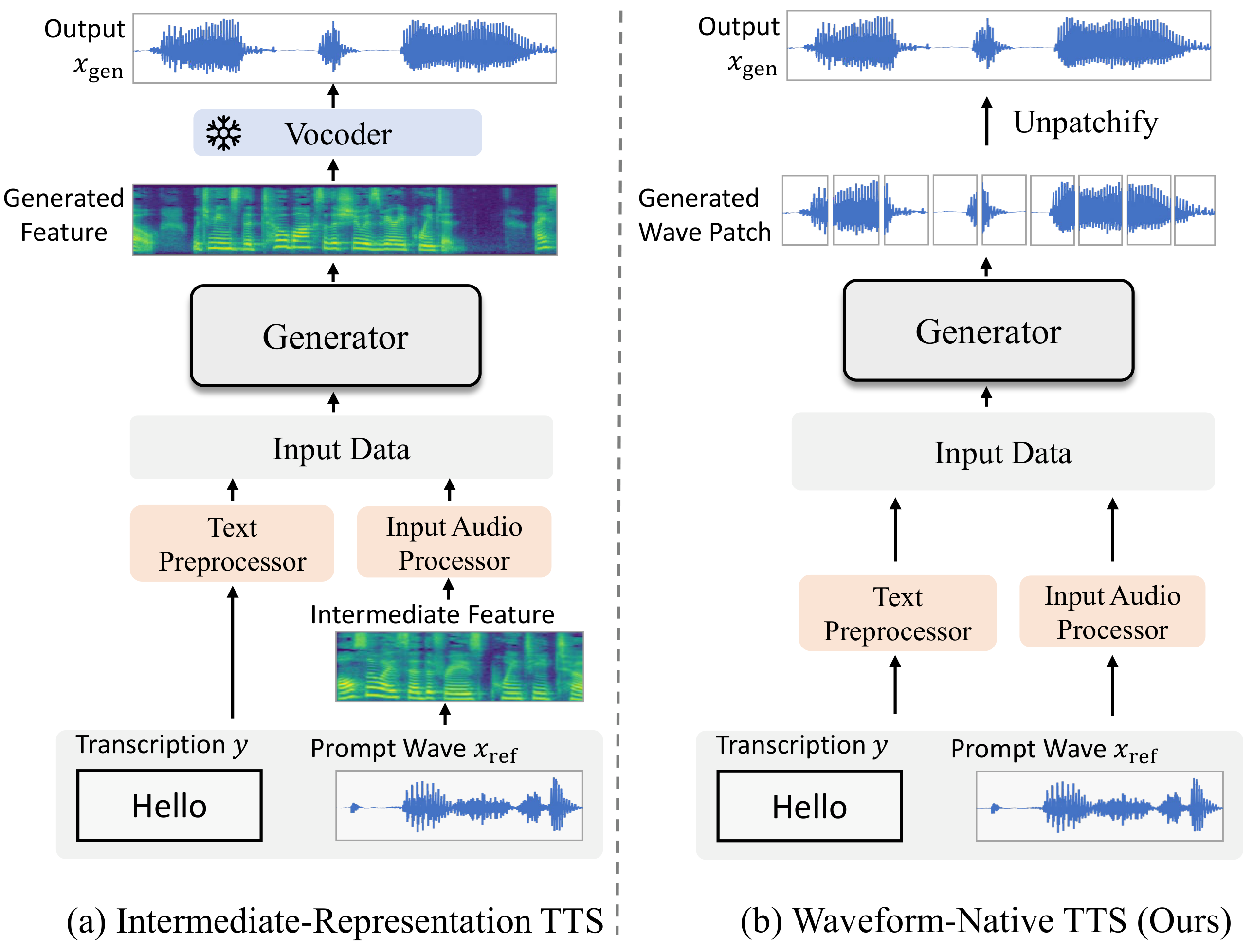
BareWave
BareWave: Waveform-Native Flow-Matching Text-to-Speech
BareWave is a waveform-native text-to-speech model that directly synthesizes waveforms from text and prompt audio without intermediate steps. It introduces new training methods to address waveform modeling challenges, enabling high-quality zero-shot voice cloning with a streamlined inference process.
Voice Conversion & Realtime Speech
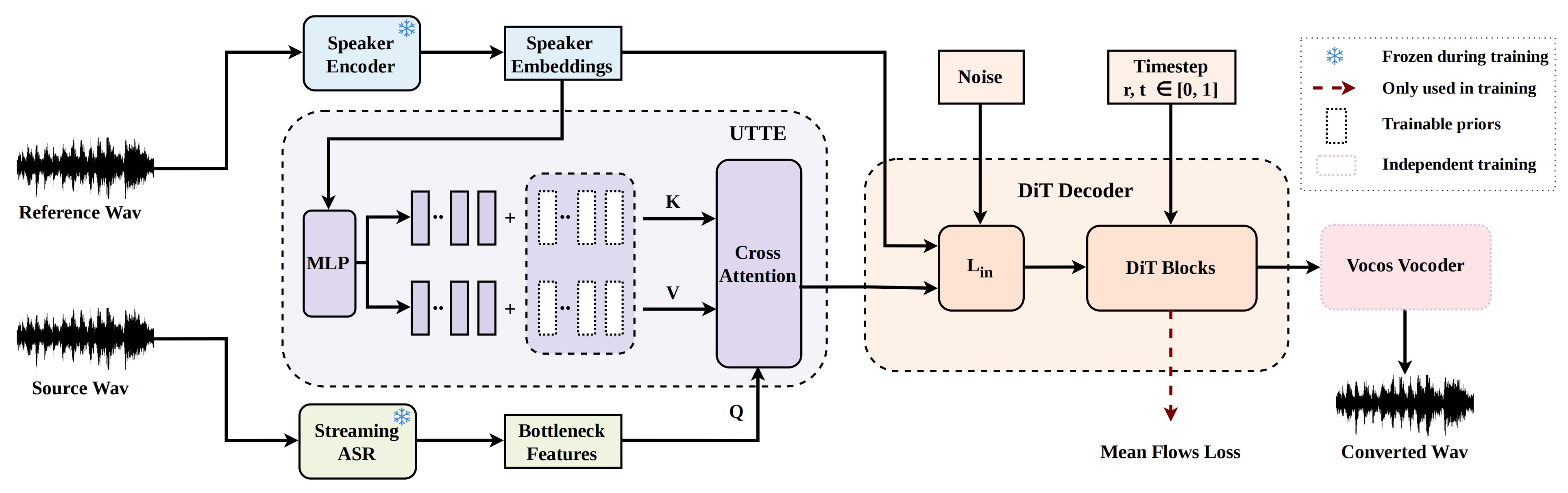
MeanVC 2
MeanVC 2: Robust Low-Latency Streaming Zero-Shot Voice Conversion
MeanVC 2 improves streaming zero-shot voice conversion by using future-receptive chunking for stable low-latency output and a universal timbre token encoder for robustness to low-quality references, enabling real-time speaker conversion with better naturalness and speaker similarity.

Palindromic-VC
From A to B to A: Palindromic Zero-Shot Voice Conversion with Non-Parallel Data
Palindromic-VC is a zero-shot voice conversion method using synthetic pairs from KNN retrieval over self-supervised features for non-parallel training and strong speaker identity preservation, generalizing across languages without parallel data.