Speech Models Get Leaner
Today’s digest spotlights faster, simpler speech systems: streaming TTS, end-to-end discrete-token training, interpretable voice control, and new ways to plug speech directly into LLMs. The common thread is practical speech intelligence with lower latency, cleaner architectures, and more controllable outputs.
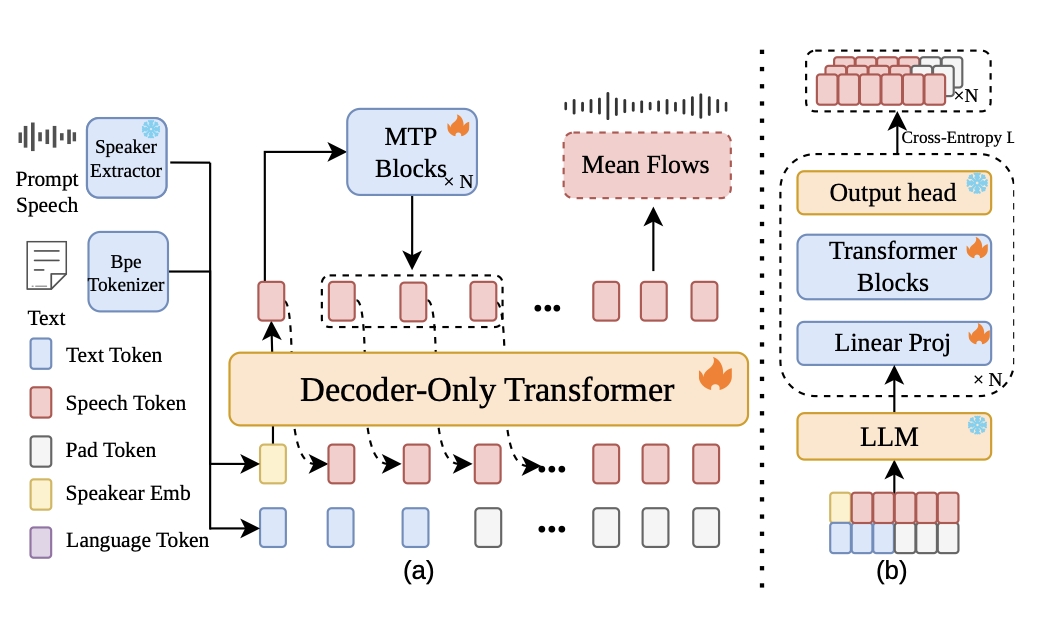
Architecture Overview of FlashTTS showing the two-stage training process for streaming and multi-token prediction. From FlashTTS.
TTS & Voice Synthesis
FlashTTS
FlashTTS: Fast Streaming TTS with MTP Acceleration and X-pred Mean Flow Distillation
FlashTTS introduces a streaming TTS framework that processes text and speech incrementally, using parallel multi-token prediction and a fast mean flow decoder to enable low-latency real-time speech synthesis. It uniquely optimizes both input streaming and decoding speed for conversational applications.
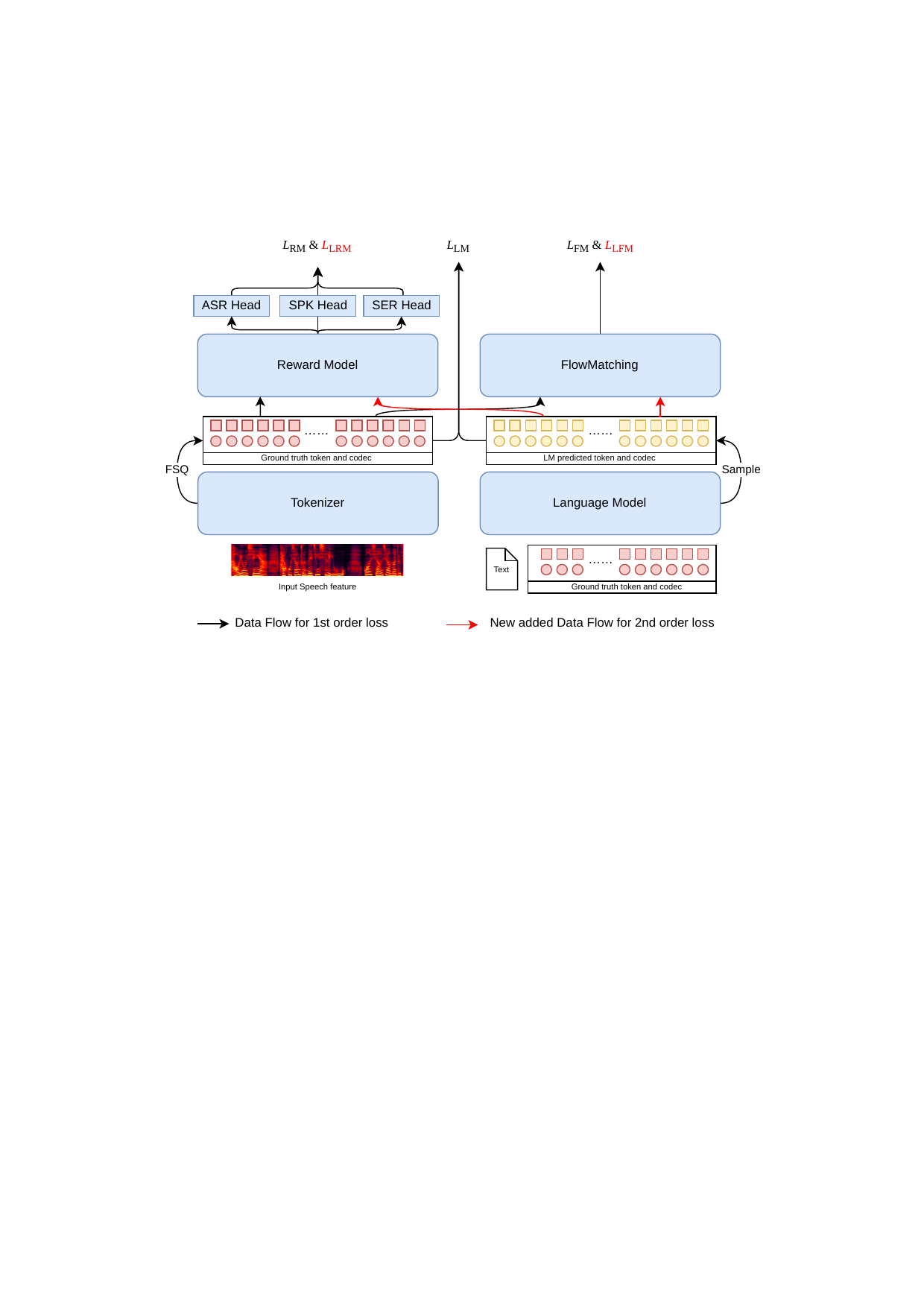
E2E Discrete Token LLM TTS
End-to-End Training for Discrete Token LLM based TTS System
This paper introduces a unified end-to-end training for discrete token-based TTS, jointly optimizing the tokenizer, LLM, flow-matching decoder, and reward model. This approach improves token quality and synthesis by reducing mismatch and tailoring tokens specifically for speech generation.
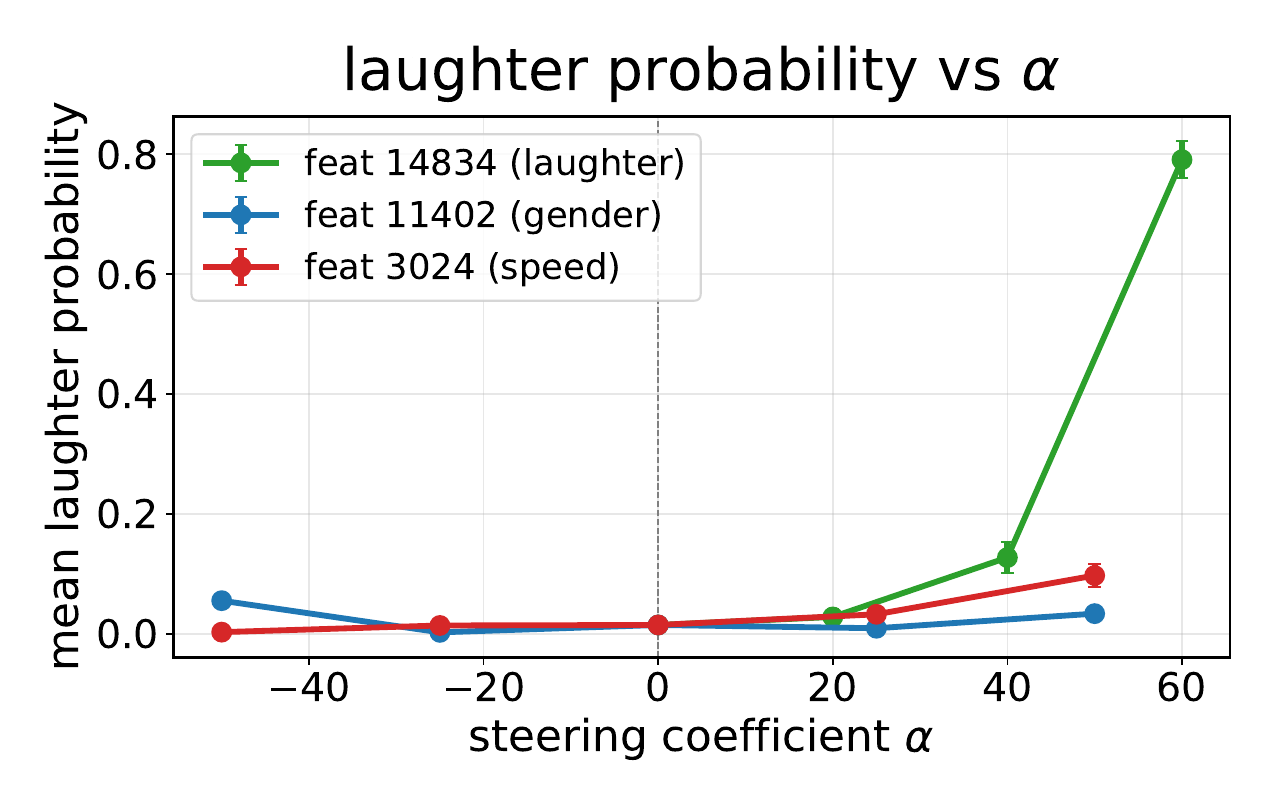
Sparse Autoencoder Steering for TTS
Interpreting and Steering a Text-to-Speech Language Model with Sparse Autoencoders
The paper uses sparse autoencoders to interpret and control features in a text-to-speech language model's shared text-speech representation. This enables causal steering of speech attributes such as laughter, speaker gender, and speech rate without altering the spoken content.
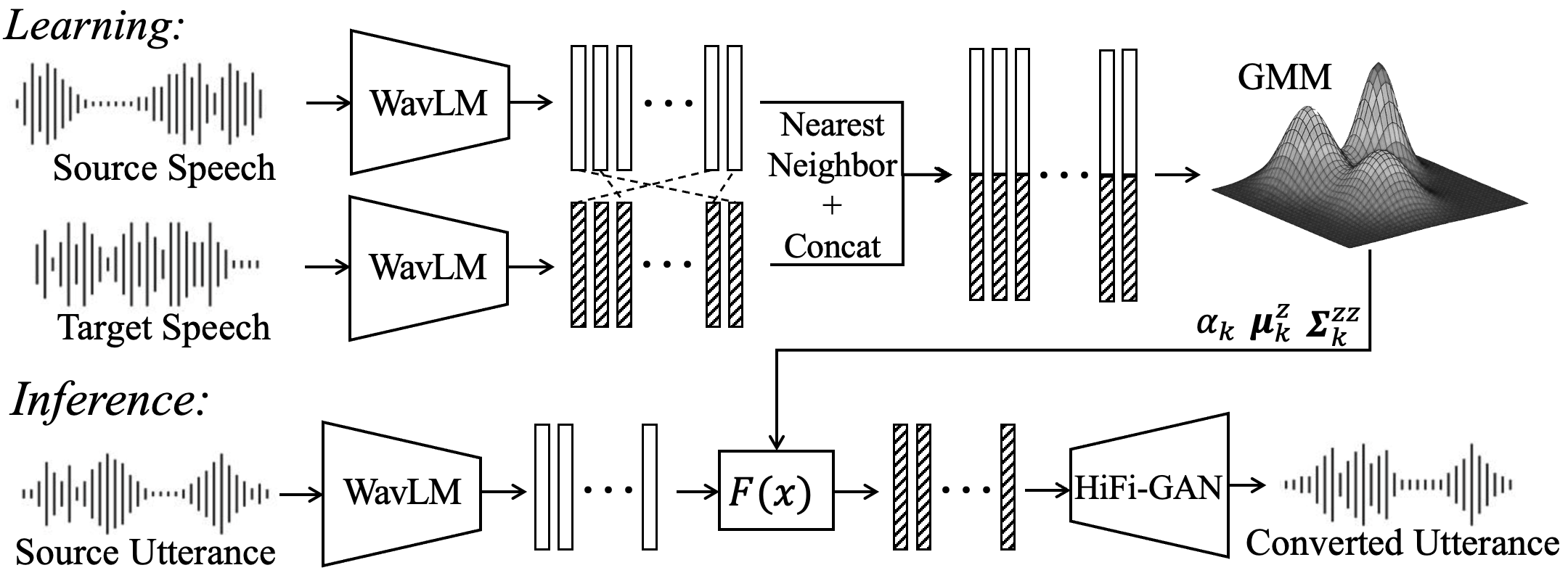
SSL-GMMVC
SSL-GMMVC: Interpretable Voice Conversion via Locally Linear GMM Transforms in Self-Supervised Representation Space
SSL-GMMVC is an interpretable voice conversion method using Gaussian mixture affine transforms in self-supervised speech space. It adapts to local structures to improve speaker similarity and reveals meaningful phonetic patterns, balancing simplicity and interpretability against complex neural models.
SpeechLLMs & Speech-Text Modeling
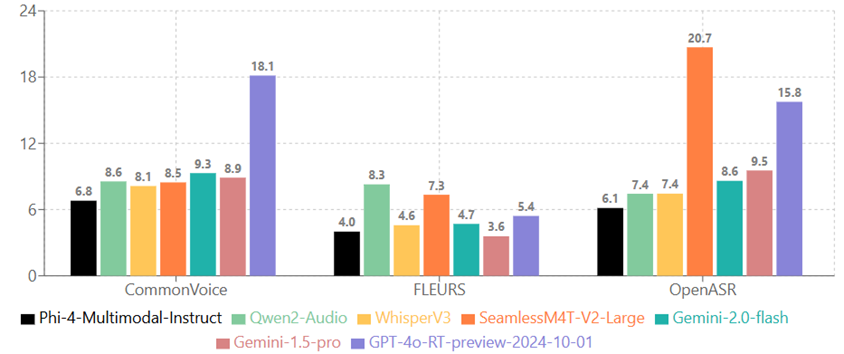
Mel-LLM
LLM can Read Spectrogram: Encoder-free Speech-Language Modeling
Mel-LLM is an encoder-free speech-language model that directly feeds Mel spectrograms into an LLM, enabling it to learn speech-text alignment without a separate speech encoder. It delivers competitive ASR results and promising TTS capabilities with a simpler, unified architecture.
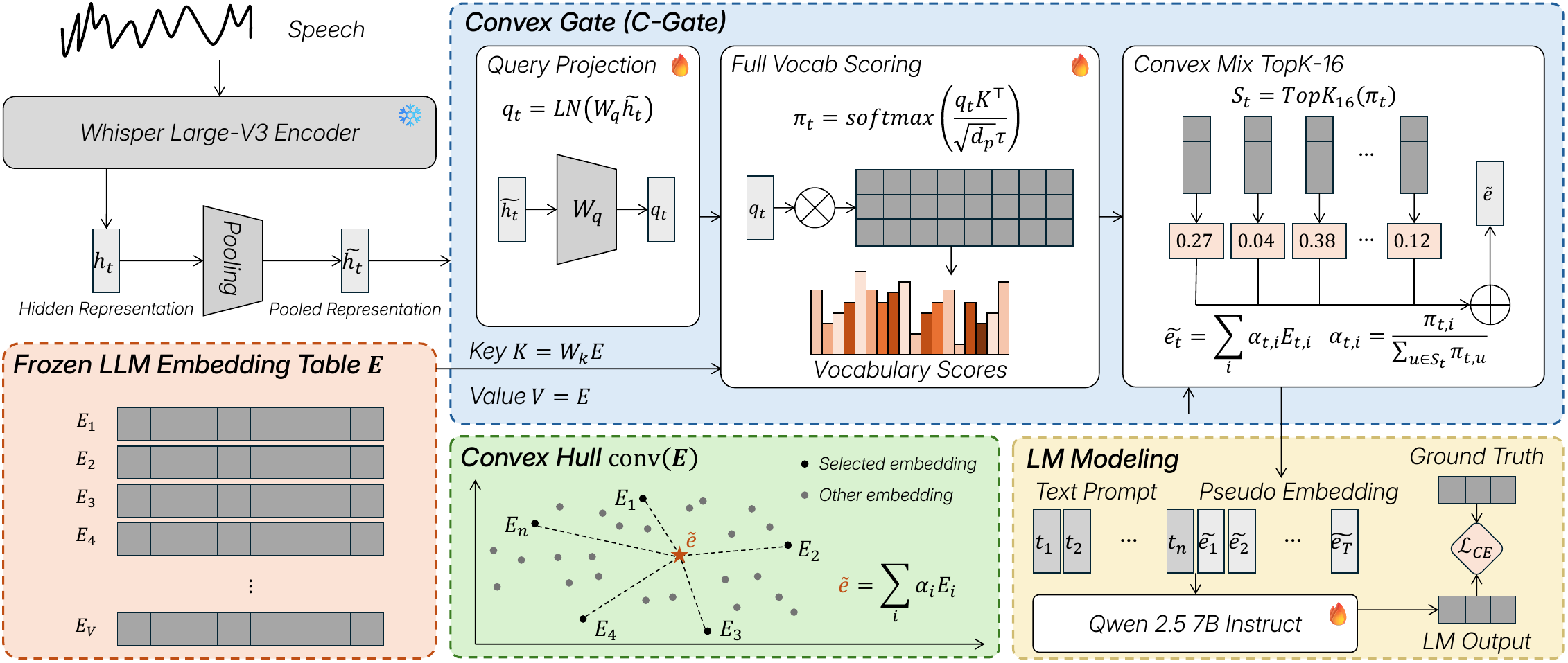
C-Gate
Is Text All You Need? Text as a Universal Information Bottleneck for Speech LLMs
C-Gate is a speech-to-LLM interface that constrains speech representations within the LLM's input embedding manifold using a convex-hull constraint. This enables continuous speech integration into frozen LLMs, preserving paralinguistic information and improving joint ASR, emotion recognition, and spoken reasoning.