Speech systems move toward richer dialogue, controllable voices, and stronger robustness
Today’s digest spans full-duplex spoken dialogue, multi-speaker scene generation, controllable TTS, and improved ASR representations. The papers focus on making speech systems more natural, more editable, and more reliable in noisy or complex settings.
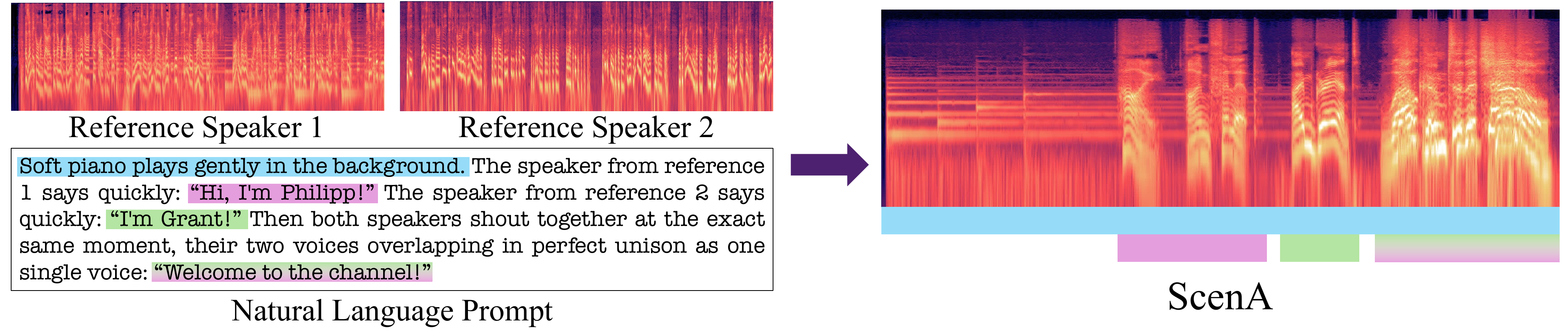
ScenA teaser illustrating multi-speaker conversational scenes synthesized from natural language prompts and reference voices with overlapping speech, paralinguistic events, and ambient sound. From ScenA.
SpeechLLMs & Spoken Dialogue
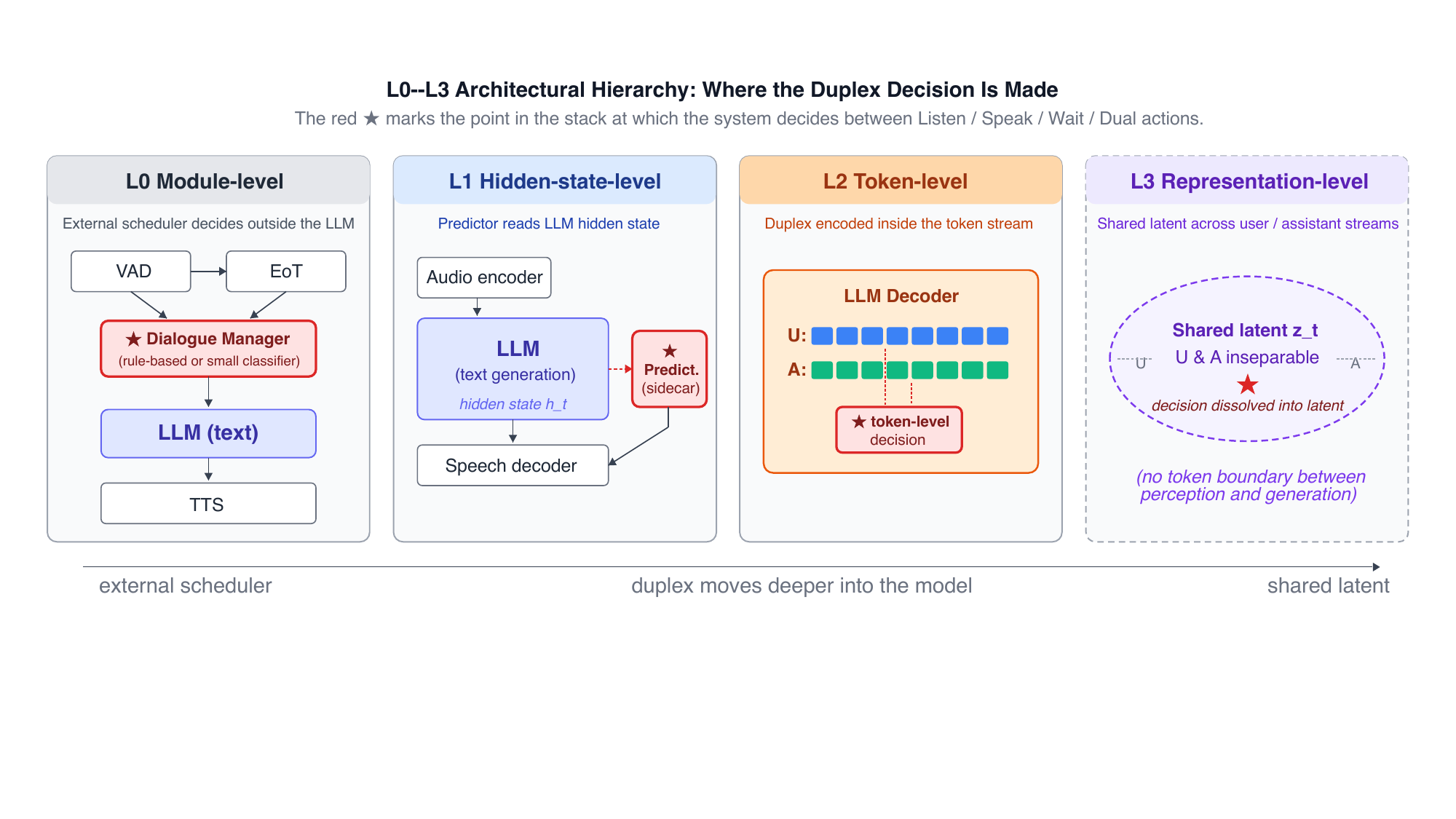
Full-Duplex Spoken Dialogue Survey
A Survey of Full-Duplex Spoken Dialogue Systems: Architectural Hierarchy, Interaction Ontology, and Decision State Machine
This paper surveys full-duplex spoken dialogue systems with a new framework that clarifies their architectural hierarchy, interaction types, and state behaviors. It audits systems and data to reveal gaps and outlines future research directions in full-duplex conversation.
ScenA
Reference-Driven Multi-Speaker Audio Scene Generation from In-the-Wild Priors
ScenA generates natural multi-speaker audio scenes from reference voices and free-form prompts without turn-based tags. It uses a high-noise training scheme ensuring speaker assignment via text, enabling rich overlapping dialogue, ambient sound, and paralinguistic events from real-world audio.
TTS & Voice Synthesis
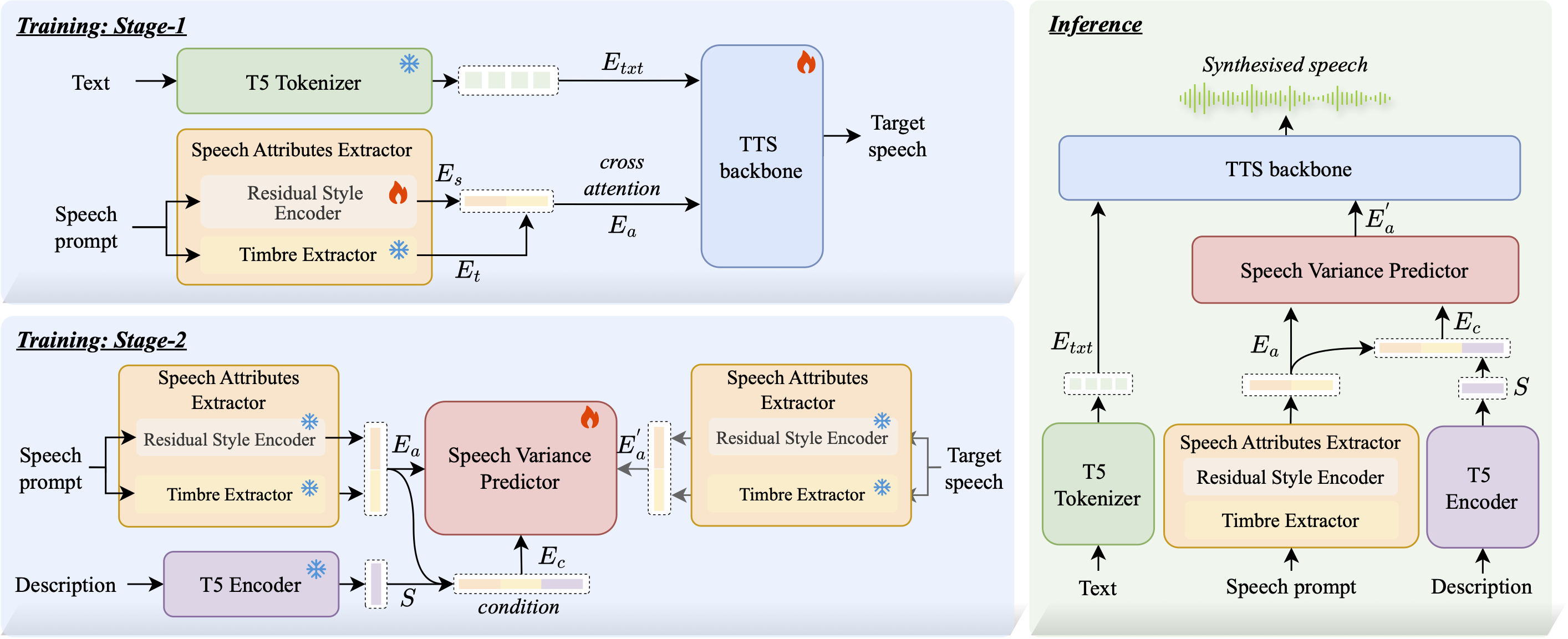
FineCombo-TTS
FineCombo-TTS: Collaborative and Precise Controllable Speech Synthesis Using Text Descriptions and Reference Speech
FineCombo-TTS uniquely combines reference speech and text descriptions for precise, flexible control of speech synthesis, jointly modeling timbre, prosody, and emotion. It learns a unified acoustic embedding and uses a text-guided flow model to edit speech attributes based on relative changes from a reference.
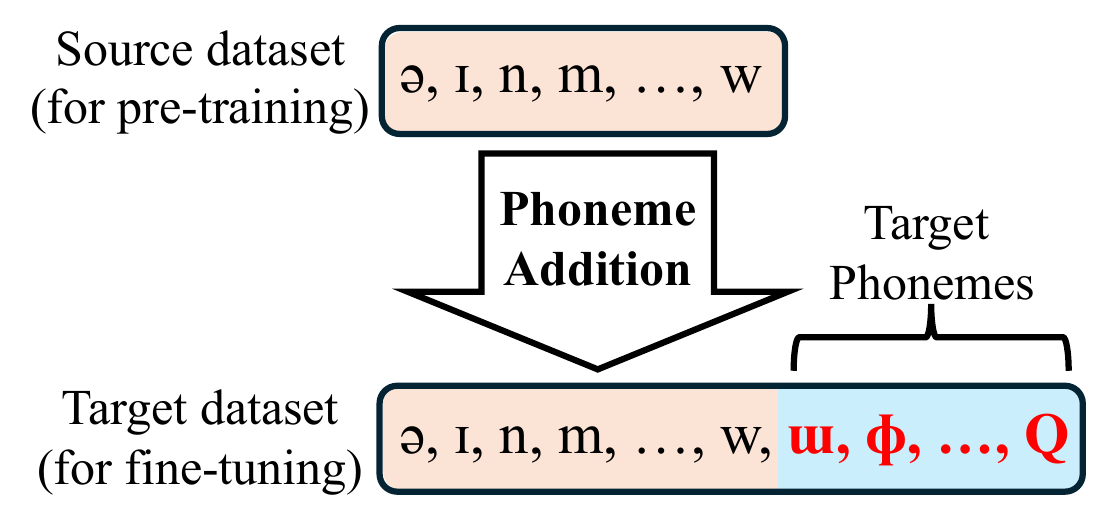
Phoneme Addition Transfer
Exploring Pre-training Benefits on Phoneme Addition through Fine-tuning in Speech Synthesis
This paper studies how pre-training impacts adding new phonemes during fine-tuning in text-to-speech. Using a synthetic phoneme-controlled setup and real cross-lingual transfer, it shows pre-training mainly boosts naturalness but offers limited help for learning new phonemes.
ASR & Speech Representation

DASH
DASH: Dual-View Self-Distillation with Multi-Layer Hidden Representations for Robust Speech Recognition
DASH is a self-distillation framework for robust speech recognition that aligns prototype assignment distributions from multiple encoder layers between clean and noisy views. This approach stabilizes training and learns noise-invariant representations, improving robustness without sacrificing clean accuracy.
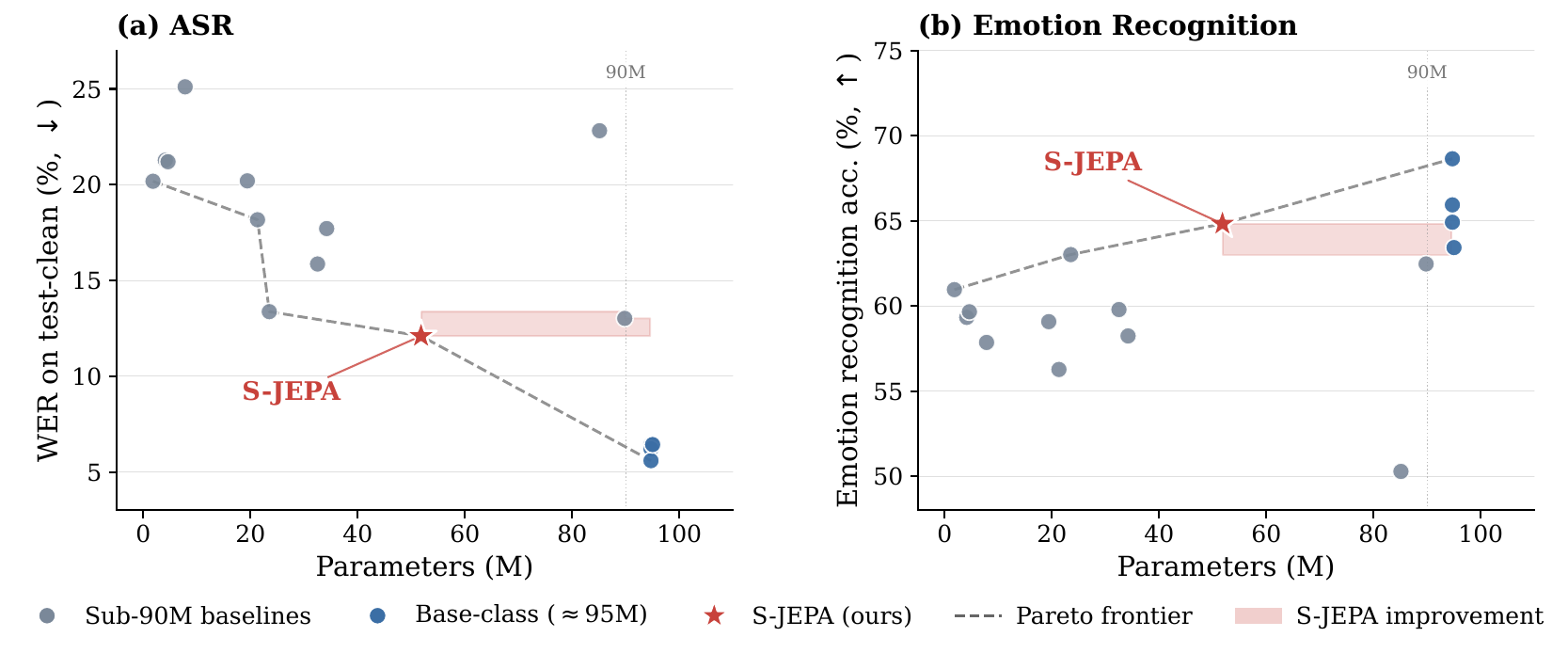
S-JEPA
S-JEPA : Soft Clustering Anchors for Self-Supervised Speech Representation Learning
S-JEPA uses soft Gaussian Mixture Model posteriors for self-supervised speech representation learning, avoiding hard cluster assignments and offline re-clustering. It continuously updates clusters online, preserving acoustic ambiguity and improving efficiency and performance on speech recognition and emotion tasks.