Speech models that talk, adapt, and translate in real time
Today’s digest spans expressive voice synthesis, low-latency speech systems, and talking avatars. From zero-shot long-form TTS to latent reasoning ASR and streaming translation, the focus is on models that sound more natural and respond faster.
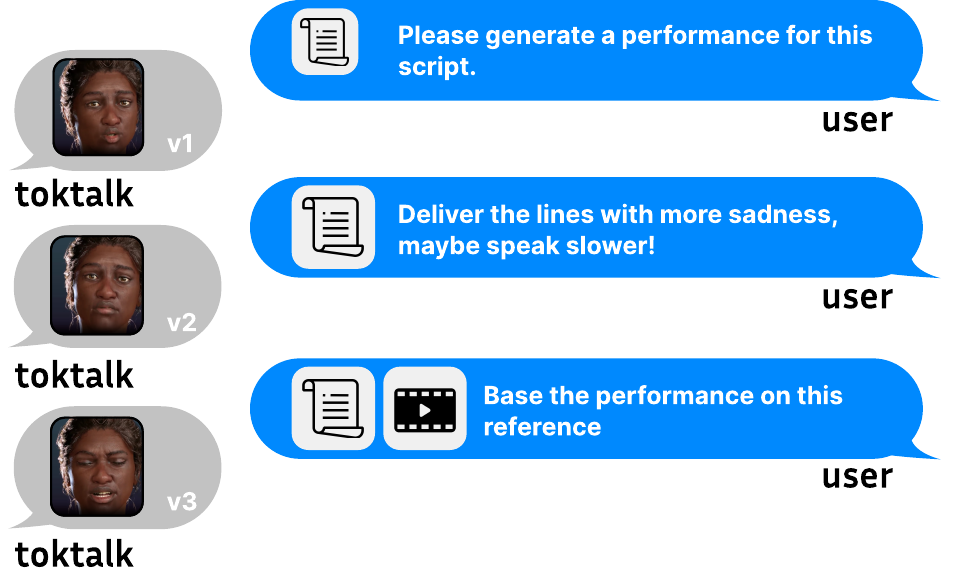
Multi-modal directorial interface for iterative control of audio and facial animation through text prompts and visual style references. From TokTalk.
Talking Avatars & Facial Animation
TTS & Voice Synthesis
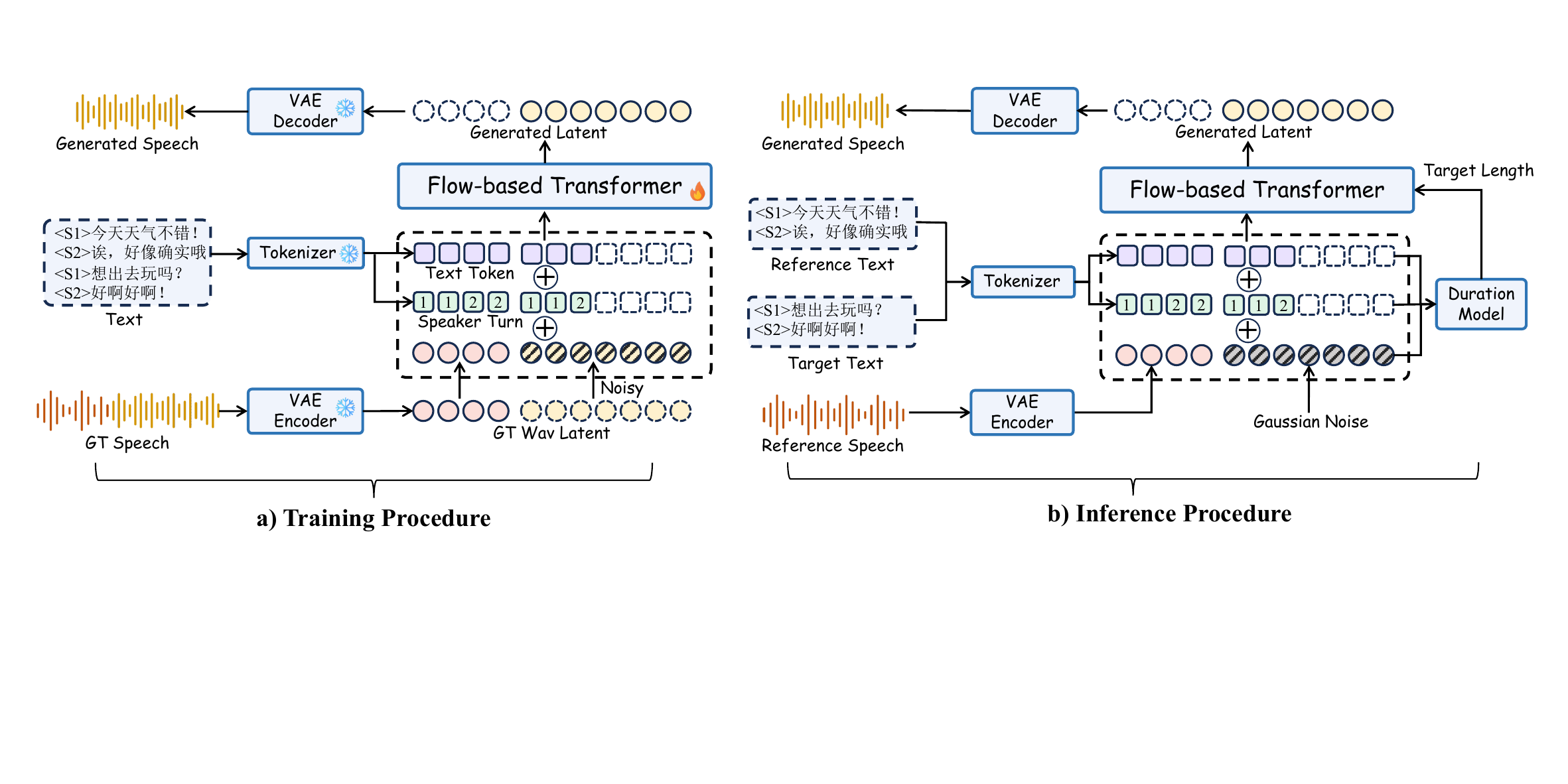
SwanVoice
SwanVoice: Expressive Long-Form Zero-Shot Speech Synthesis for Both Monologue and Dialogue
SwanVoice is a zero-shot TTS system for expressive long-form speech synthesis in monologue and multi-speaker dialogue. It models entire conversations to keep acoustic consistency and smooth speaker transitions, outperforming typical turn-by-turn methods in expressiveness and coherence.
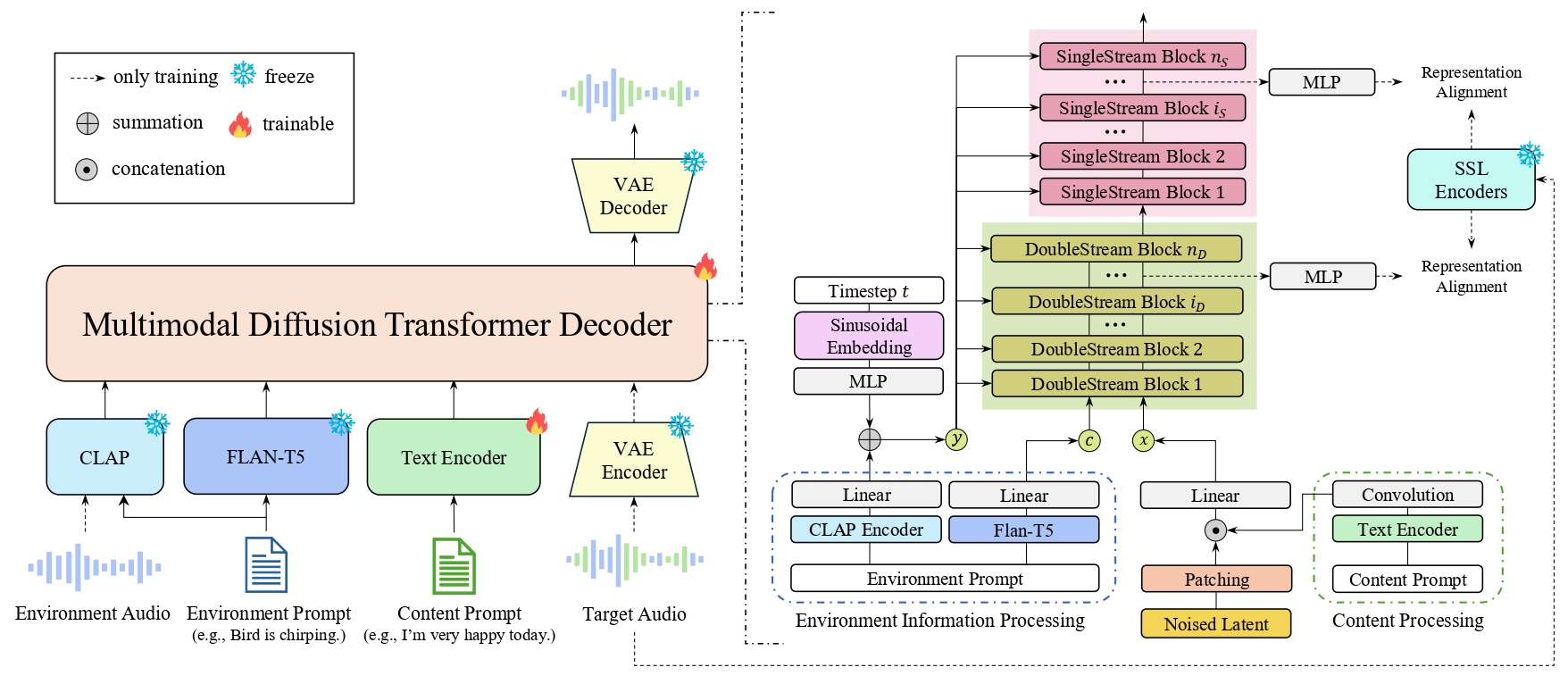
ImmersiveTTS
ImmersiveTTS: Environment-Aware Text-to-Speech with Multimodal Diffusion Transformer and Domain-Specific Representation Alignment
ImmersiveTTS synthesizes speech seamlessly integrated within environmental sounds by modeling transcript-aligned speech and text-conditioned environment together. It uses a multimodal diffusion transformer and domain-specific alignment to improve naturalness and coherence beyond prior text-to-speech methods.
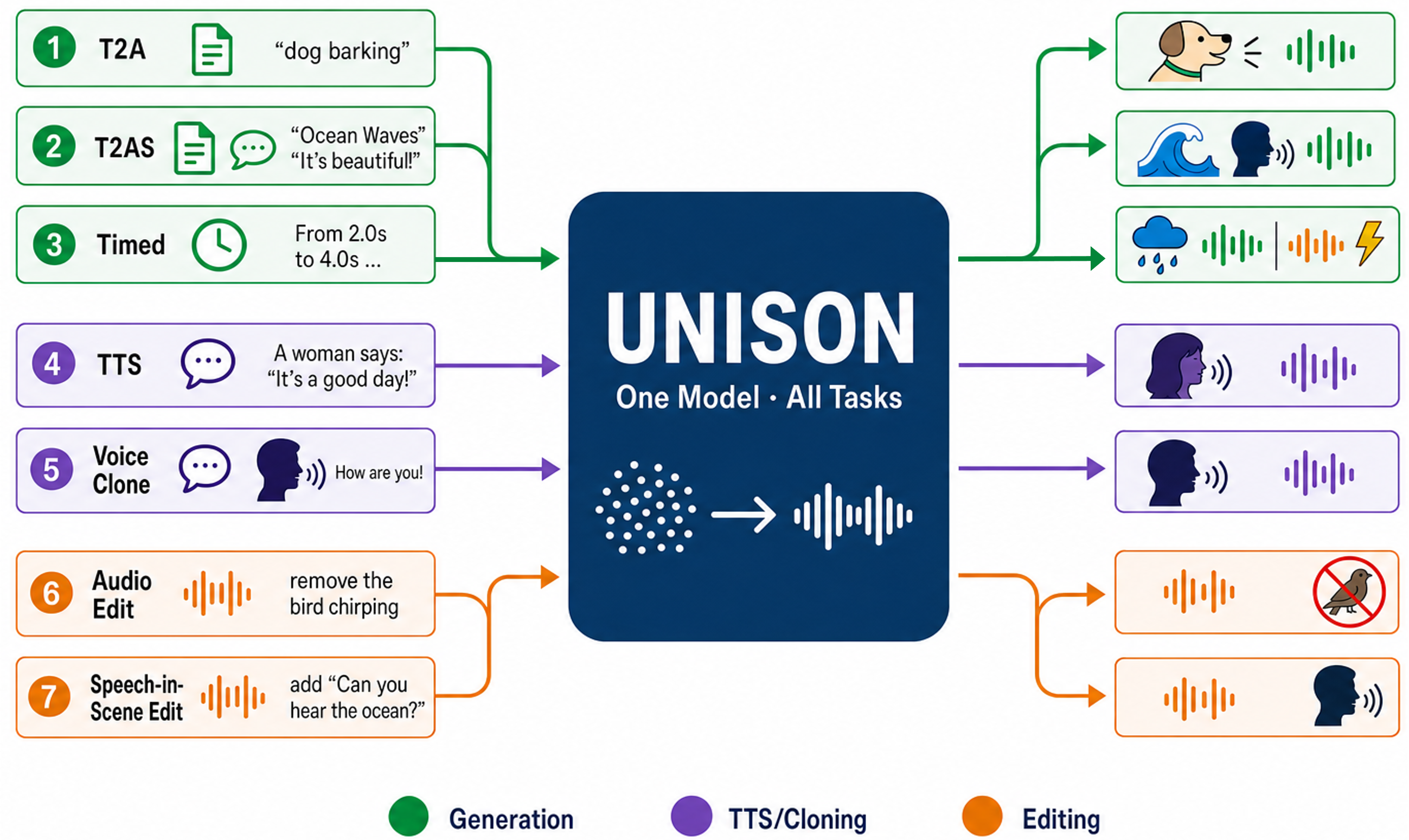
UNISON
UNISON: A Unified Sound Generation and Editing Framework via Deep LLM Fusion
UNISON unifies speech, sound generation, and audio editing into a single model using layer-wise deep LLM fusion, enabling versatile tasks like text-to-audio and zero-shot speaker cloning efficiently with one architecture.
SpeechLLMs, ASR & Low-Latency Speech Systems
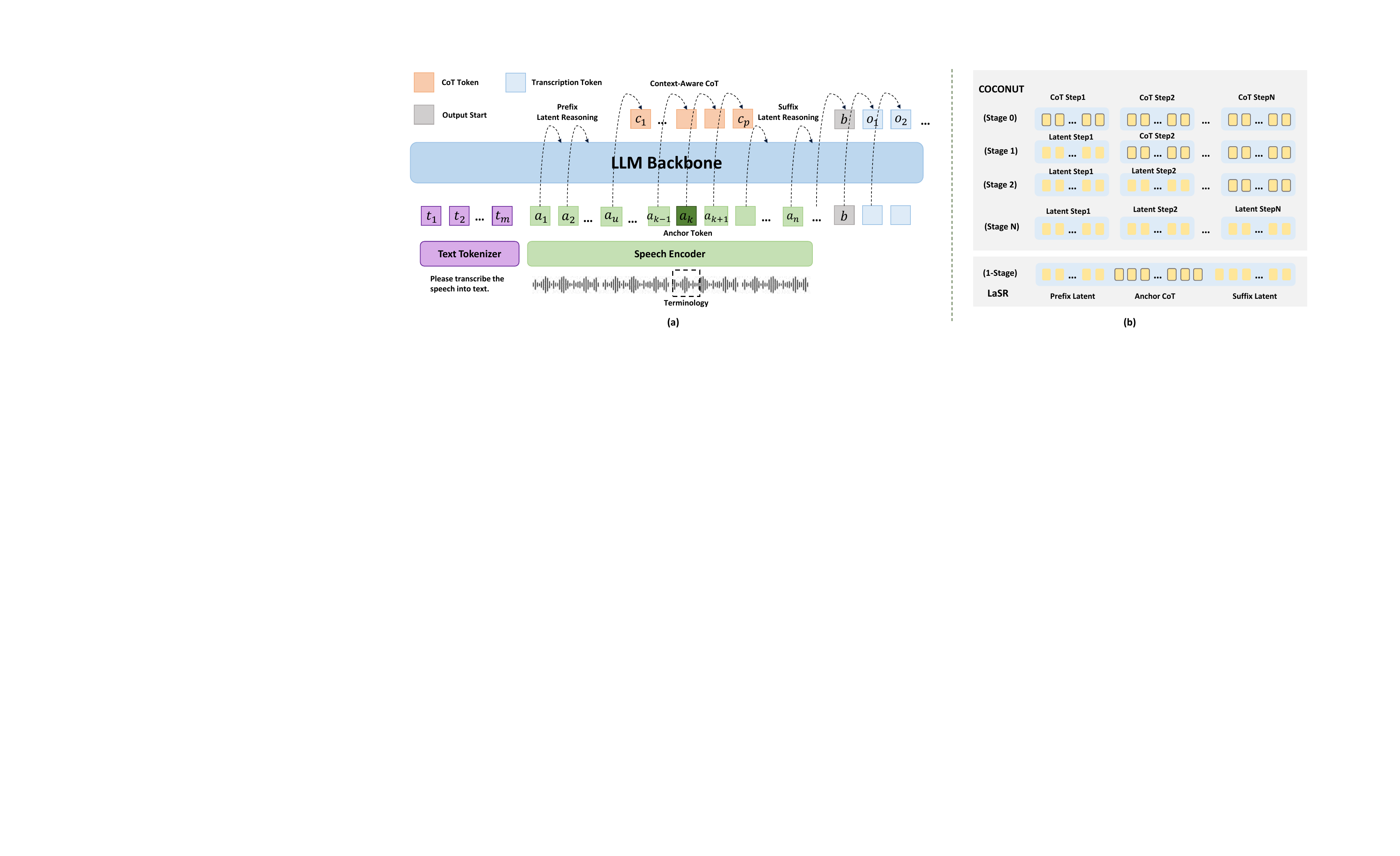
LaSR
LaSR: Context-Aware Speech Recognition via Latent Reasoning
LaSR proposes a training method that embeds latent reasoning within the speech token stream to enable context-aware recognition of specialized terminology. This approach improves transcription accuracy on rare academic terms without adding inference latency by aligning reasoning supervision to the acoustic timeline.
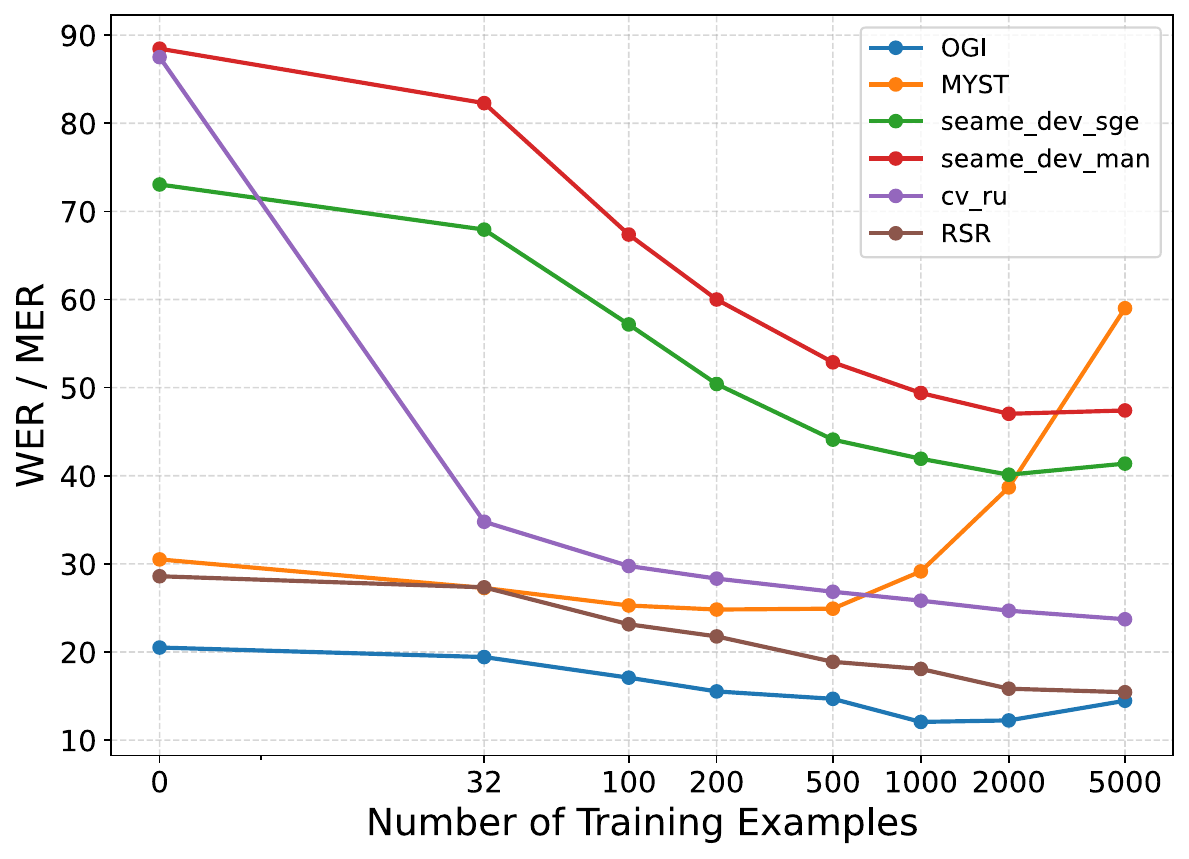
SALSA
SALSA: Speech Aware LLM Adaptation via Learned Steering Activation Vectors
SALSA adapts speech-aware large language models by learning layer-wise steering vectors with a supervised objective, boosting out-of-domain speech robustness. It aligns acoustic representations with pretrained language models without tuning model weights, enabling efficient, effective speech adaptation.
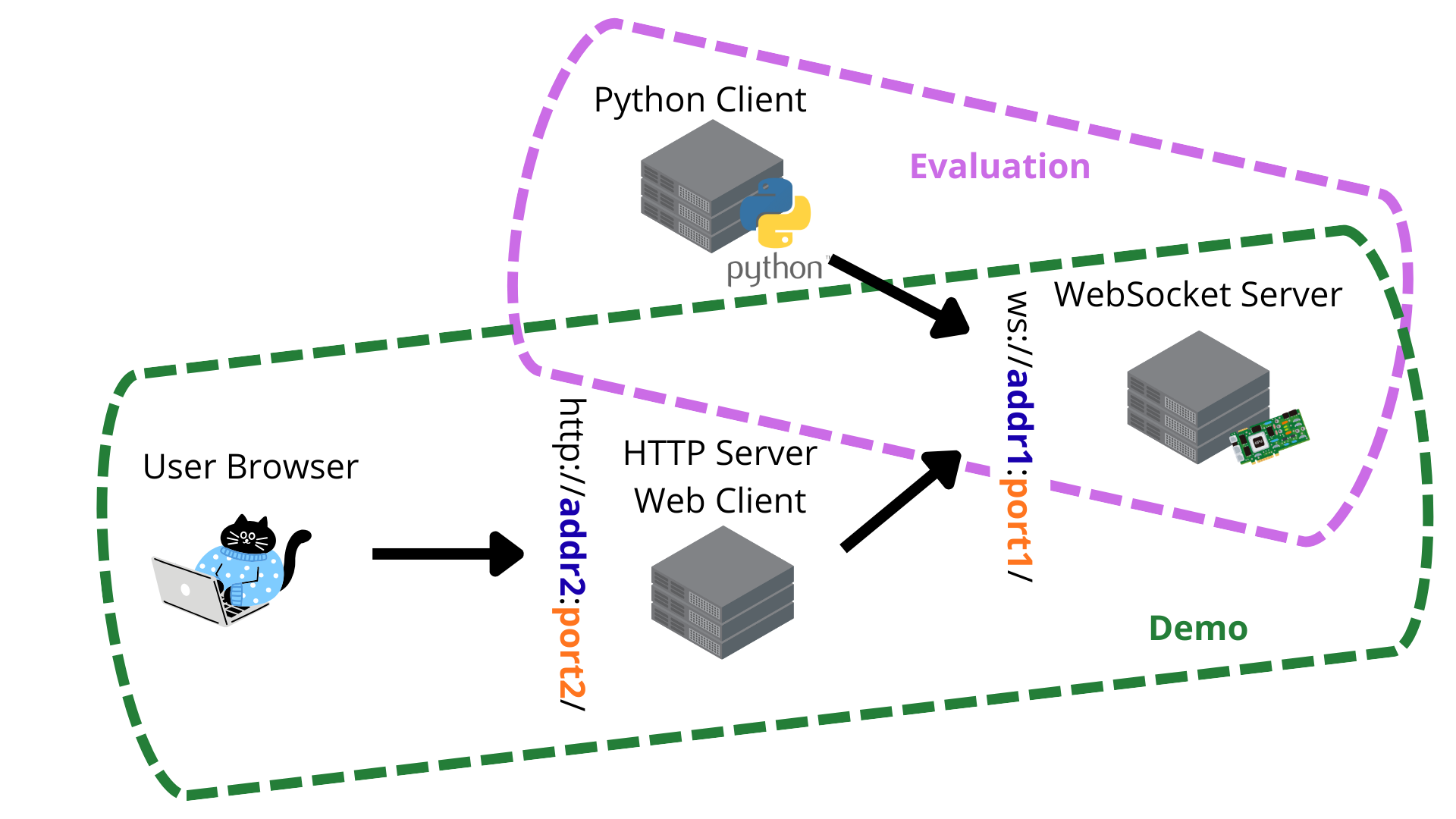
DOA
DOA: Training-Free Decoder-Only Attention Policy for Long-Form Simultaneous Translation with SpeechLLMs
DOA is a training-free policy that uses decoder self-attention as a proxy alignment for streaming long-form simultaneous speech translation. It enables low-latency, high-quality translation with off-the-shelf SpeechLLMs without retraining, by guiding read/write decisions from self-attention signals.