Controlling speech, audio, and avatars
Today’s digest spans new ways to shape how machines speak, listen, and move: from universal audio generation and controlled TTS to stronger ASR alignment and adaptive speech encoders. It also includes a fresh step toward smoother digital-human motion from sparse sensor input.
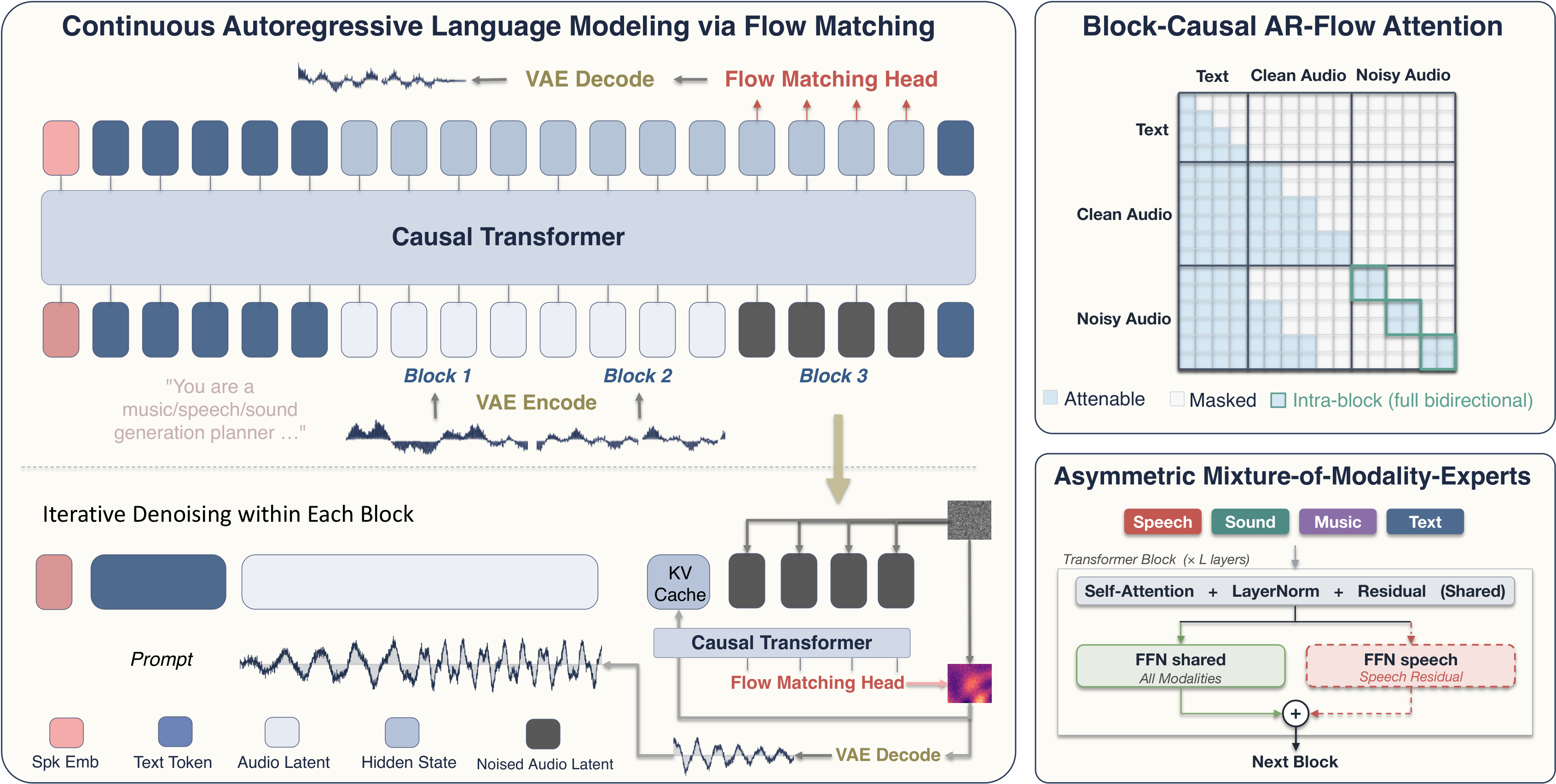
AudioCALM architecture overview illustrating the continuous autoregressive model with flow-matching head and asymmetric experts for universal audio generation. From AudioCALM.
Digital Humans & Avatar Motion
SpeechLLMs & Spoken Audio Generation
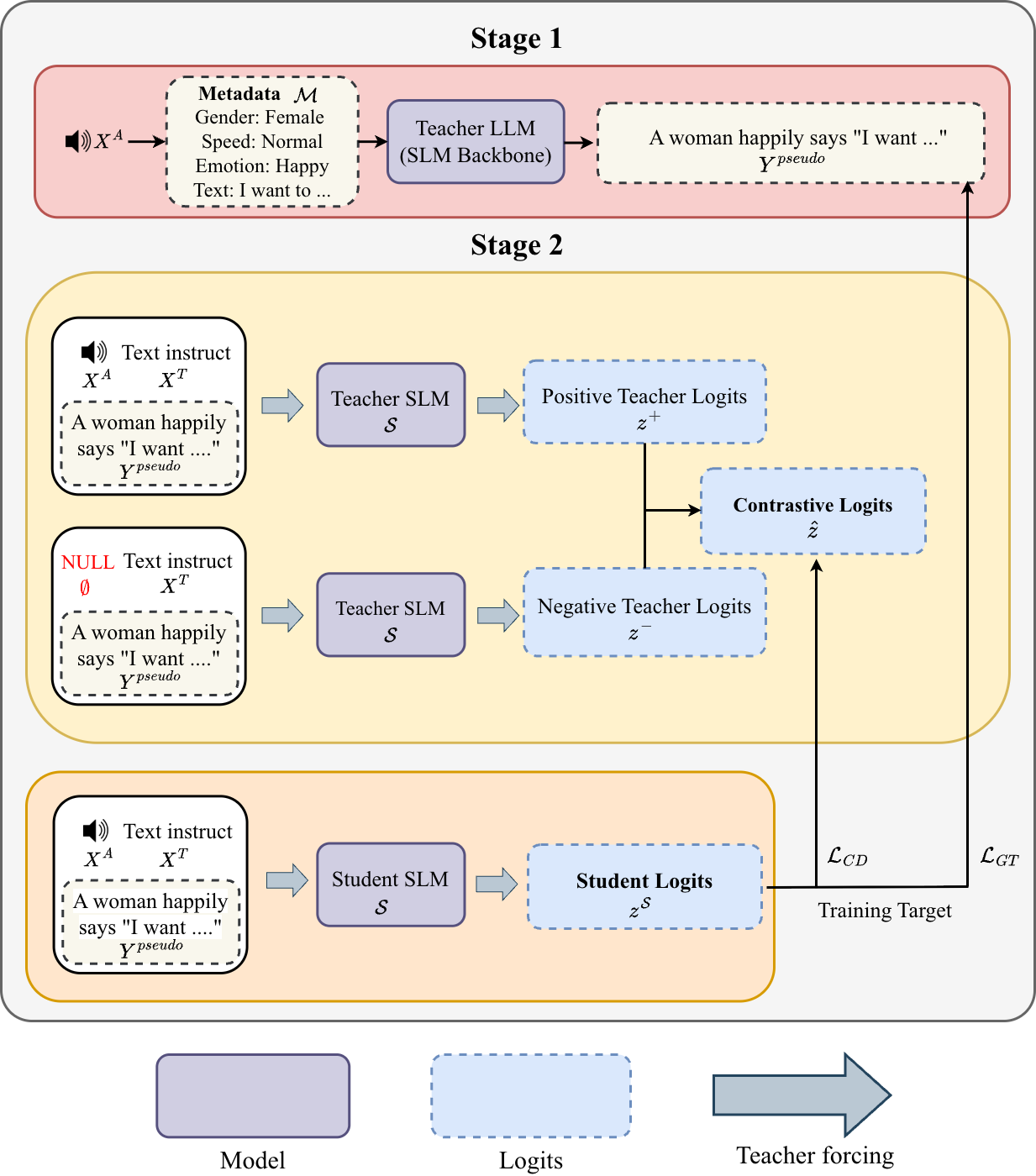
CAAD
CAAD: Contrastive Audio-Aware Distillation for Efficient Speech Language Models
CAAD distills contrastive audio-aware decoding into a student model to improve speech language understanding with efficiency and stronger acoustic grounding. It uses synchronized teacher forcing and metadata-based pseudo-ground truths to distill contrastive reasoning without inference-time overhead.
AudioCALM
AudioCALM: Continuous Autoregressive Language Modeling for Universal Audio Generation
AudioCALM is a universal audio generation model that autoregressively predicts continuous audio latents to unify speech, sound, and music synthesis. It balances modality differences with asymmetric experts and descriptive conditioning for high-quality, variable-length, end-to-end audio generation.
TTS & Voice Synthesis
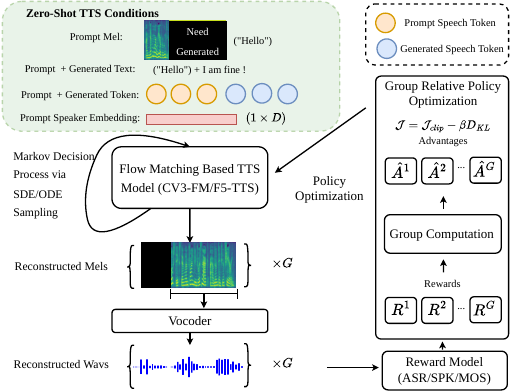
FlowTTS-GRPO
FlowTTS-GRPO: Online Reinforcement Learning with Multi-Objective Reward Optimization for Flow-Matching Based Text-to-Speech
FlowTTS-GRPO uses online reinforcement learning to fine-tune flow-matching TTS models with multi-objective rewards for speaker similarity, quality, and intelligibility. It enables exploration via stochastic sampling without auxiliary models, improving voice cloning and cross-lingual transfer.
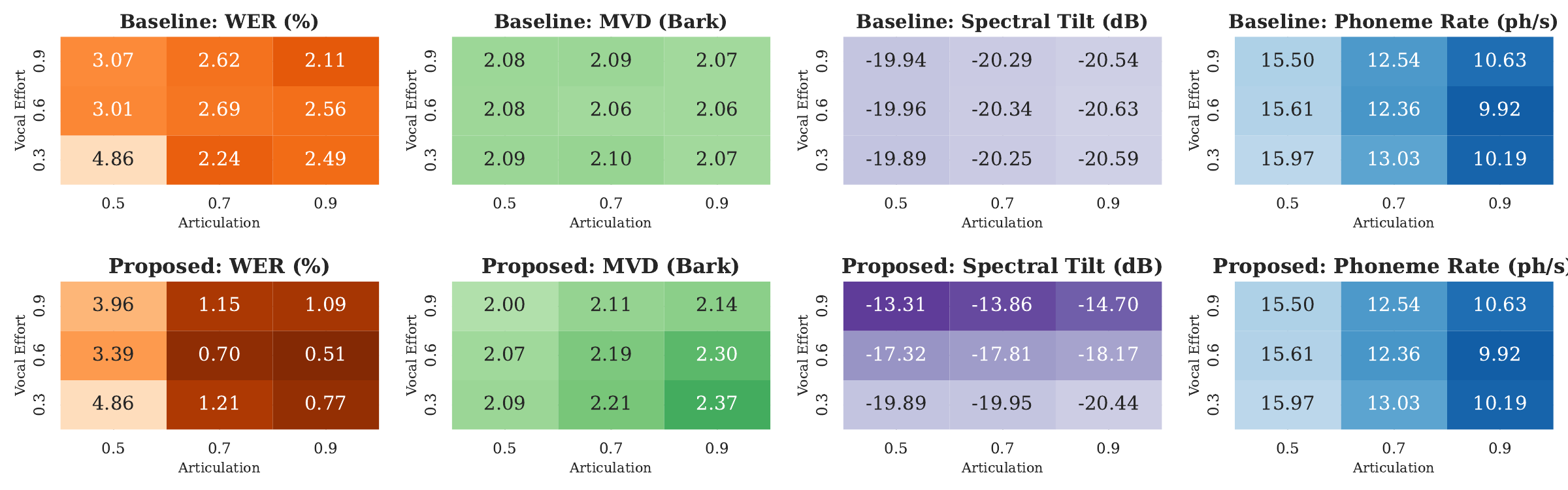
LombardTTS
Synthesizing the Lombard Effect: Multi-Level Control of Speech Clarity and Vocal Effort in TTS
This paper presents a TTS system that independently controls vocal effort and articulation to simulate the Lombard effect, enhancing speech clarity and intelligibility in noisy conditions. It enables continuous multi-level and word-level control for nuanced, context-specific speech emphasis.
ASR Architectures & Adaptation
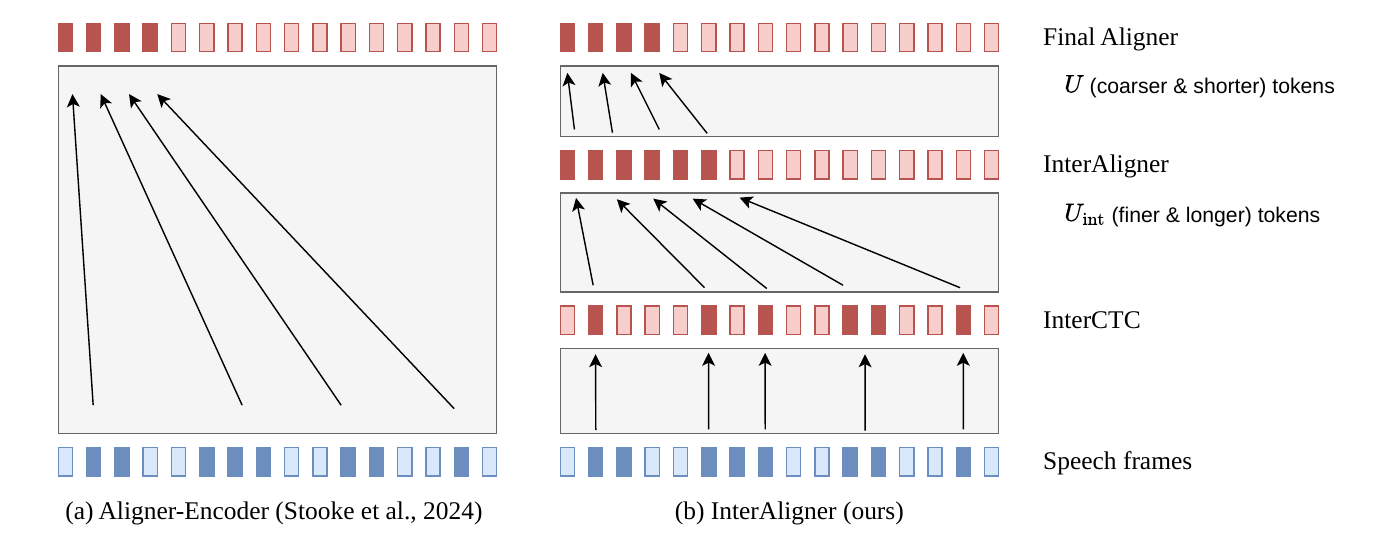
InterAligner
Progressive Alignment Objectives for Aligner-Encoder based ASR
InterAligner enhances Aligner-Encoder ASR by adding progressive alignment objectives at intermediate layers, guiding the encoder to form monotonic alignment gradually. This approach stabilizes training and improves recognition, especially on long utterances, outperforming methods using only final-layer alignment.
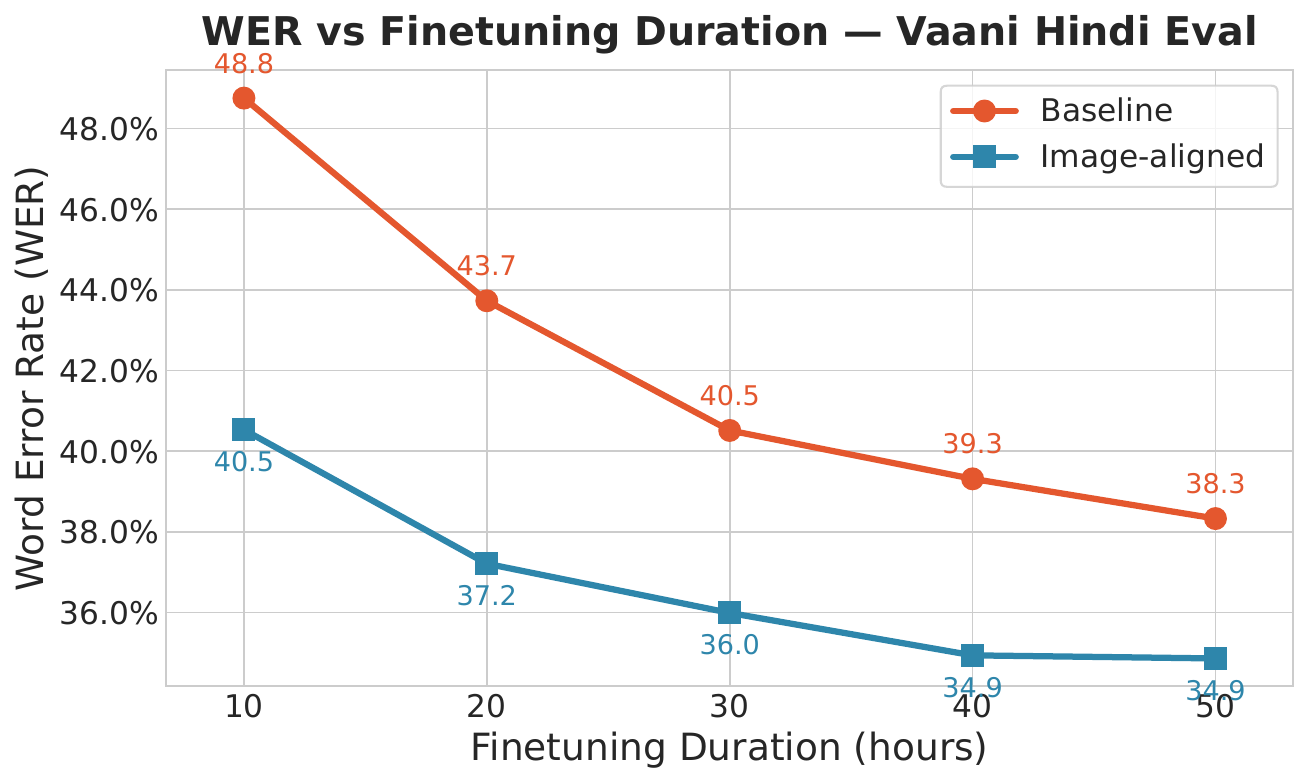
Audio-Image Alignment for Low-Resource ASR
Audio--Image Alignment as a Continued-Pretraining Stage Improves Low-Resource ASR
This paper proposes an intermediate pretraining step using audio-image pairs to adapt pretrained audio encoders without transcripts. This stage improves ASR performance in low-resource languages by enhancing representation robustness and transferability before supervised fine-tuning.