Talking Agents Get More Human
Today’s digest spans real-time lip sync and facial animation, stereoscopic digital humans, and speech models that handle turn-taking, interruptions, and paralinguistic cues more naturally. It also includes progress in multilingual TTS and higher-fidelity voice generation.
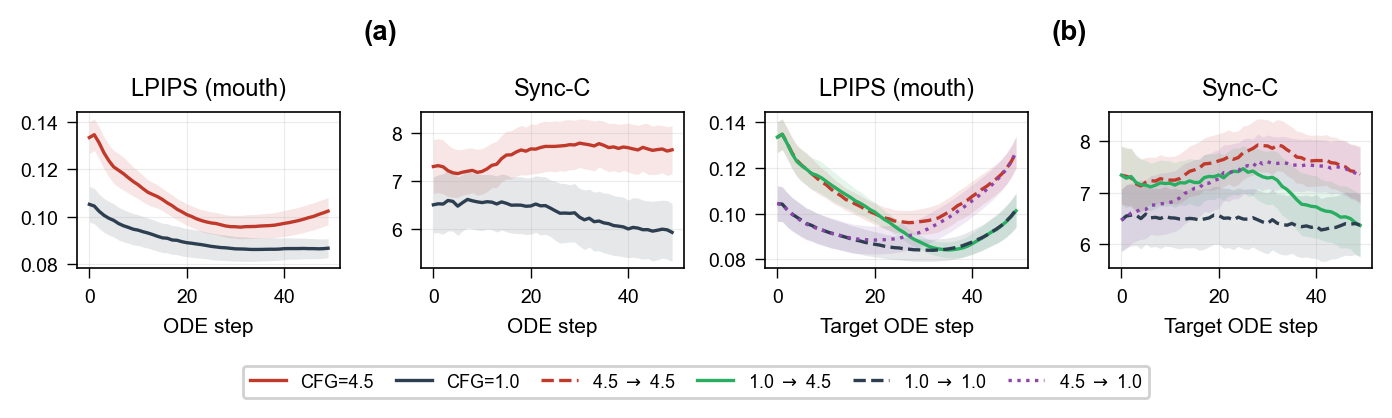
CFG fidelity-sync tradeoff: full trajectory analysis and 2x2 schedule factorial From Lip Forcing.
Talking Avatars, Lip Sync & Face Animation
Lip Forcing
Lip Forcing: Few-Step Autoregressive Diffusion for Real-time Lip Synchronization
Lip Forcing is the first autoregressive diffusion method for real-time lip-sync in talking-head videos. It distills a large bidirectional diffusion teacher into fast causal students using a novel two-step inference and lip-sync rewards, enabling photorealistic lip motion in streaming applications.
3DMEAD-ARKit Facial Animation
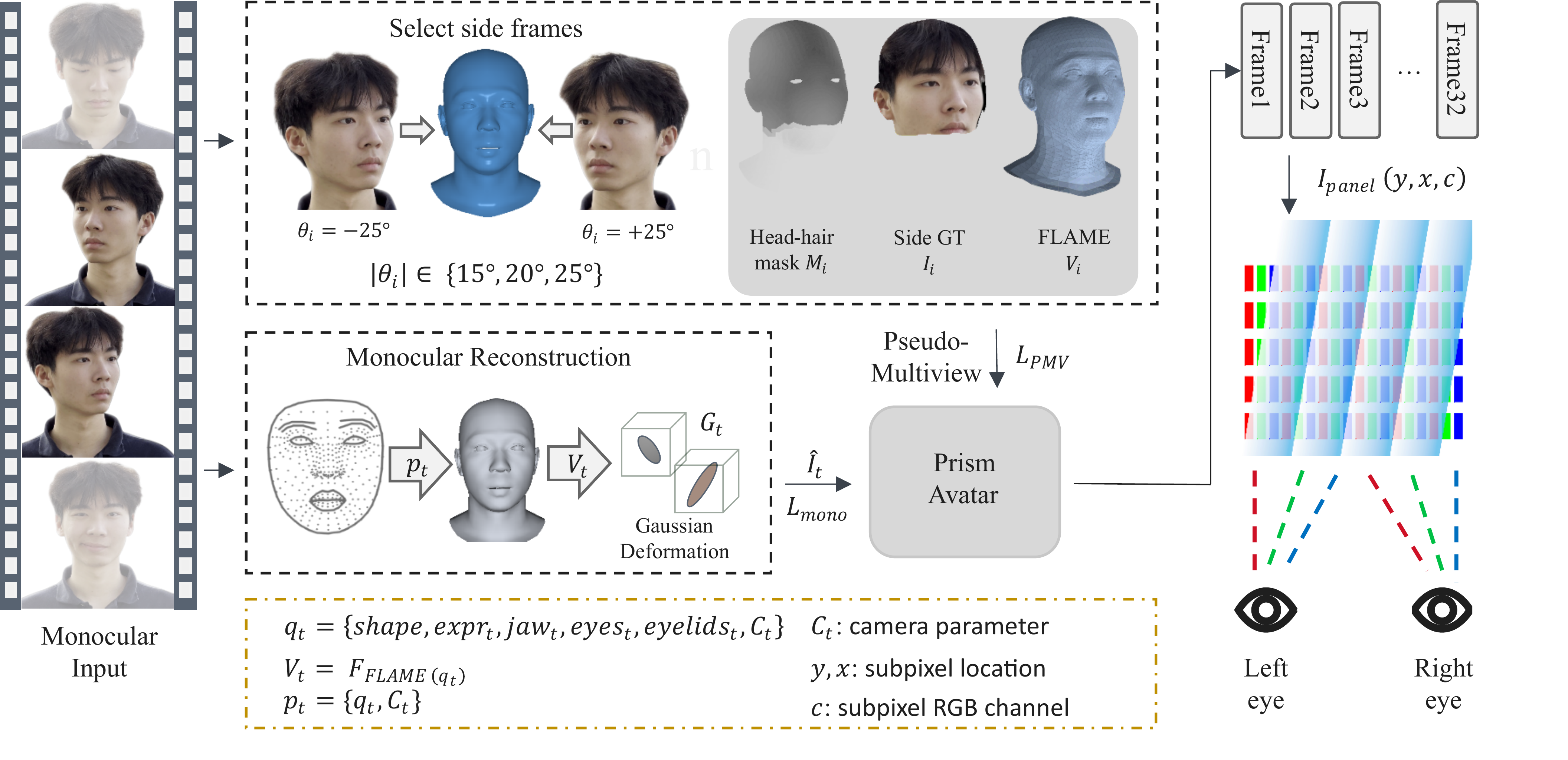
Deploying Speech-Driven 3D Facial Animation in Unreal Engine for Production-Ready Digital Humans
This paper introduces a deployable system that enables speech-driven 3D facial animation in Unreal Engine using ARKit-compatible blendshapes. It bridges academic research and production pipelines, allowing real-time, emotion-controllable digital human animation usable in game engines.
Digital Humans & 3D Avatars
SpeechLLMs & Voice Agents
Multi-Faceted Interactivity Alignment
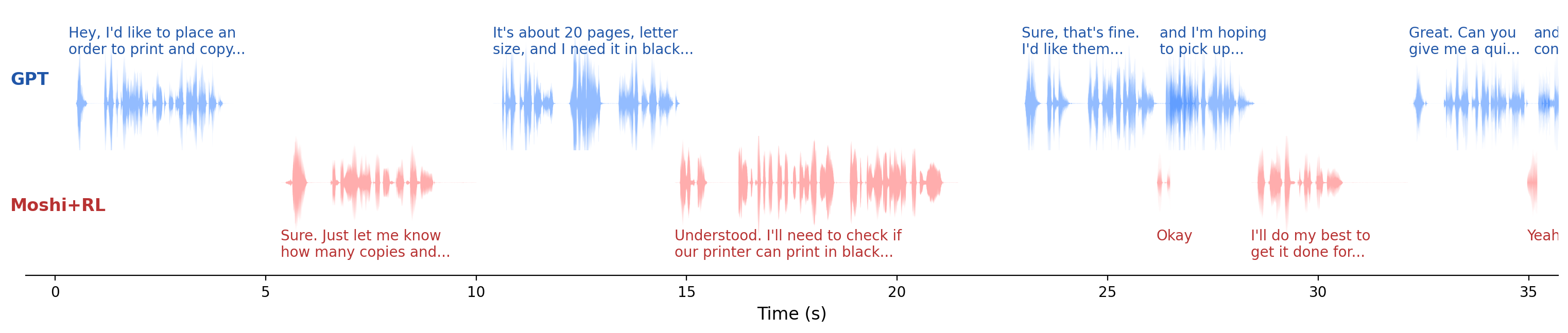
Multi-Faceted Interactivity Alignment in Full-Duplex Speech Models
This work improves full-duplex spoken dialogue models via reinforcement learning, optimizing conversational timing and behaviors such as pauses, turn-taking, backchannels, and interruptions using real human audio segments and specialized rewards while preserving response quality.
State Inertia Activation Steering
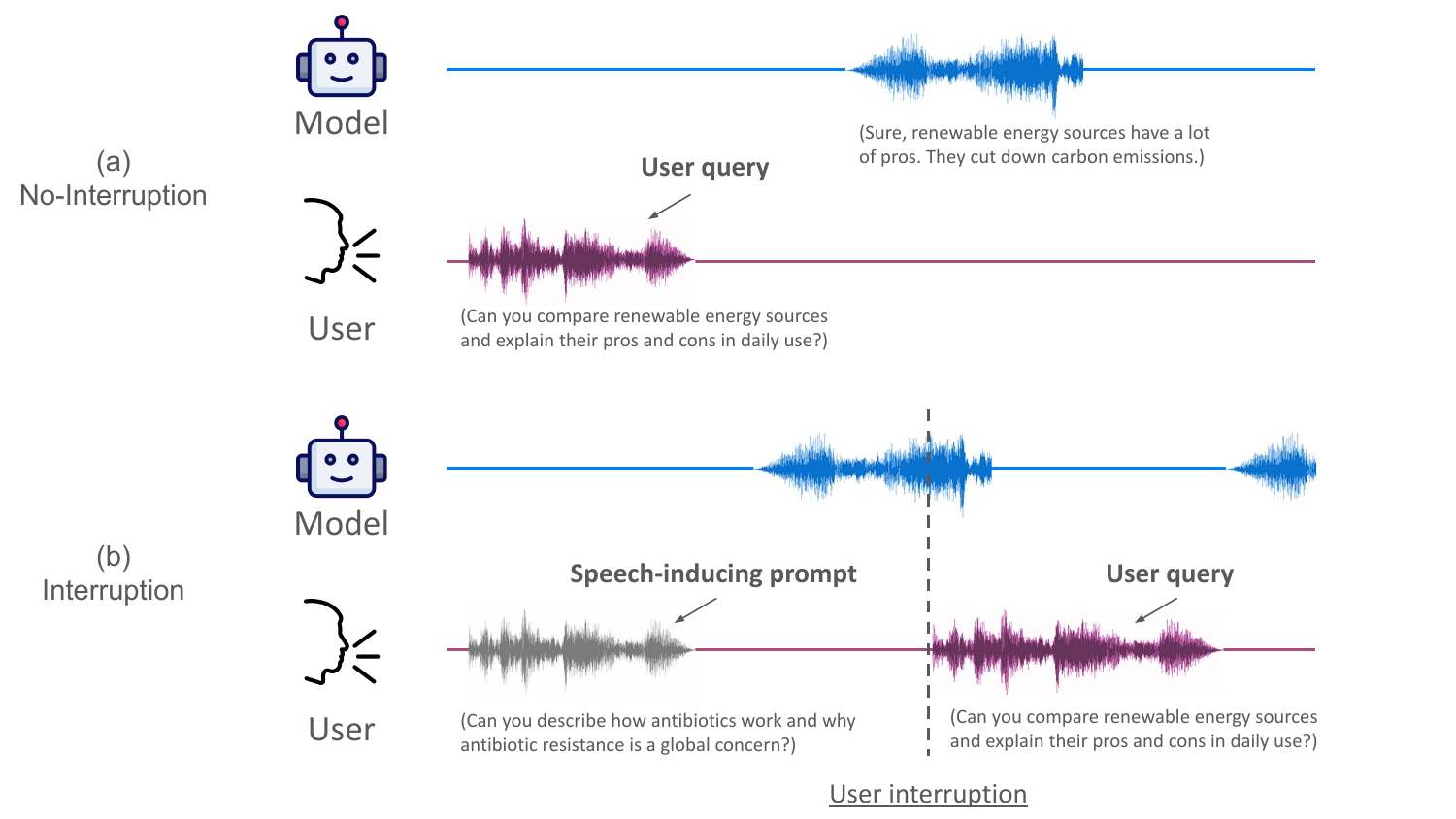
Overcoming State Inertia in Full-Duplex Spoken Language Models via Activation Steering
This paper identifies delayed internal state transitions in full-duplex spoken language models that cause missed user interruptions. It introduces activation steering to shift the model between speaking and listening modes, improving immediate comprehension during interruptions without additional training.
ParaBridge
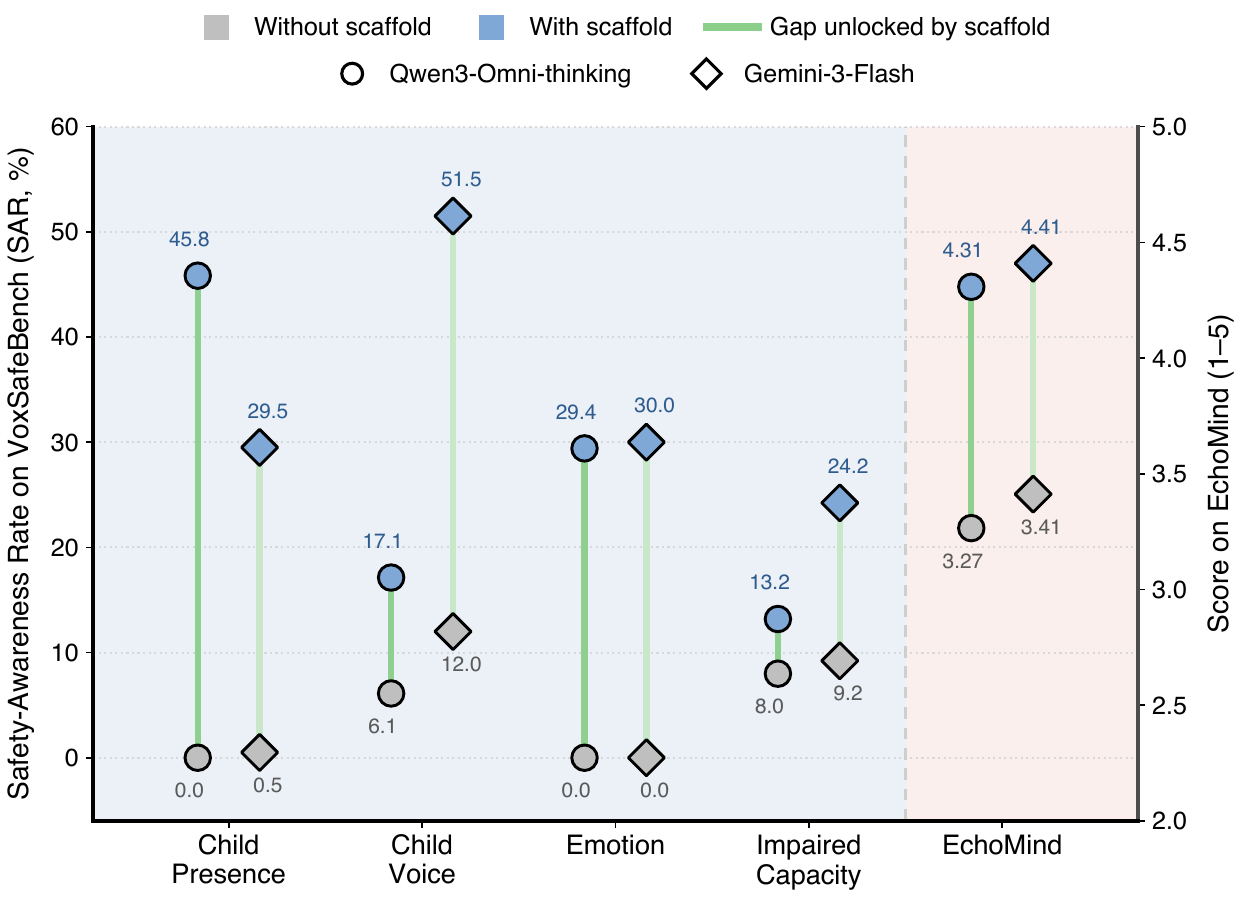
ParaBridge: Bridging Paralinguistic Perception and Dialogue Behavior in Speech Language Models
ParaBridge closes the gap between paralinguistic perception and dialogue behavior in speech language models by distilling scaffold-conditioned behaviors into scaffold-free responses. This method enhances the model's use of non-lexical speech cues in open-ended conversation without extra labels or external rewards.
TTS & Voice Synthesis
UR-BERT
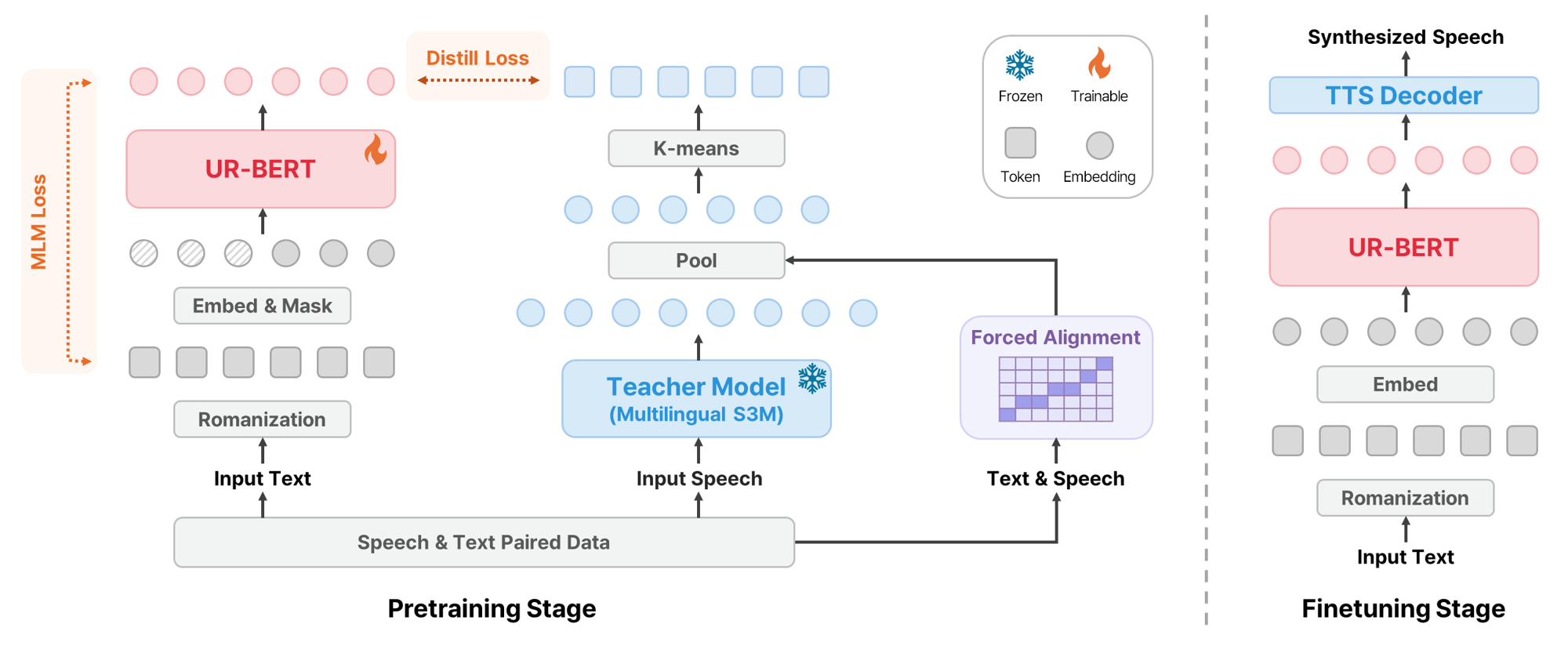
UR-BERT: Scaling Text Encoders for Massively Multilingual TTS Through Universal Romanization and Speech Token Prediction
UR-BERT is a Romanized transcription-based text encoder for massively multilingual TTS. It scales to 495 languages without phoneme systems and uses speech token prediction to improve phonetic fidelity and alignment, enabling strong results especially for low-resource and unseen languages.
SARA
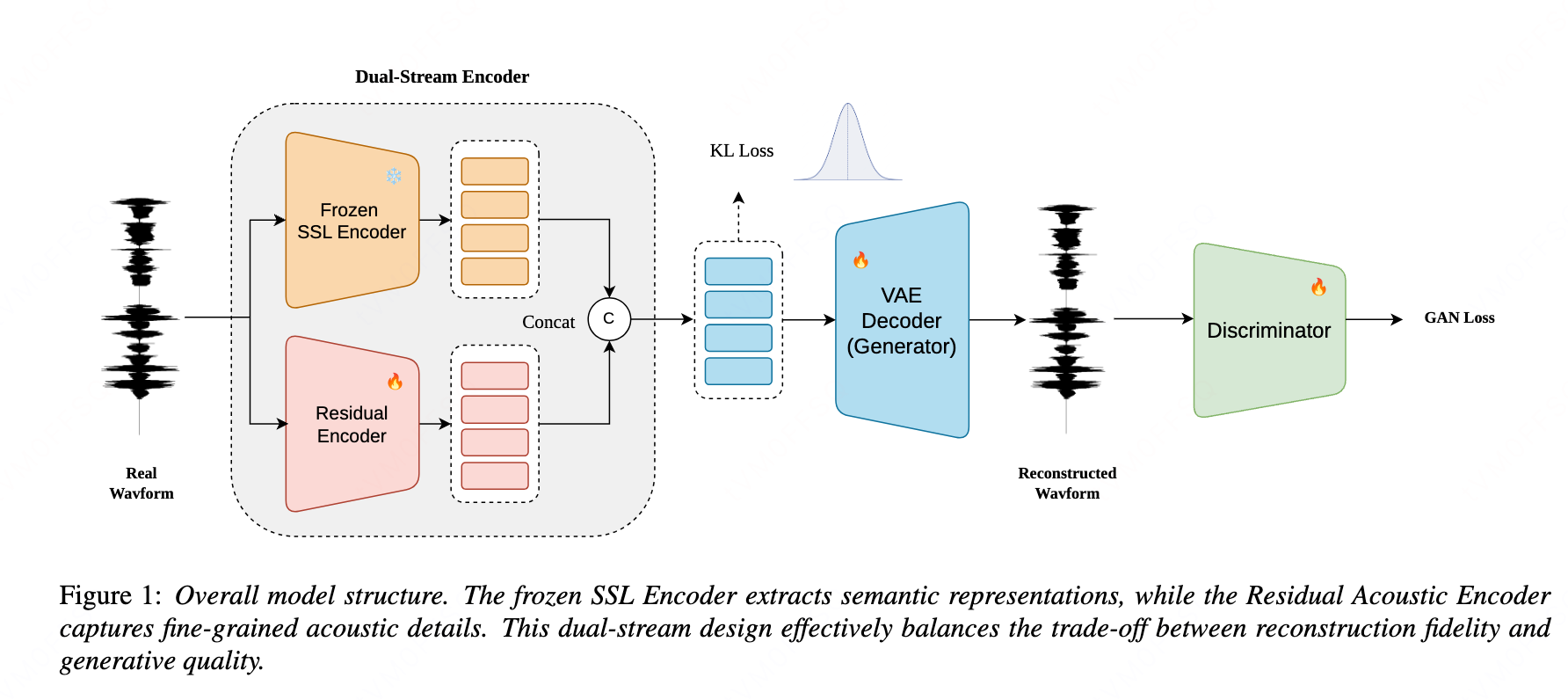
SARA: A Dual-Stream VAE for High-Fidelity Speech Generation via Integrating Semantic and Acoustic Representations
SARA is a dual-stream VAE that integrates frozen semantic and residual acoustic representations to improve zero-shot text-to-speech. This fusion balances speech fidelity with content accuracy, enabling natural, expressive, and efficient speech generation without complex regularization.