Streaming Speech, Lip Sync, Turn-Taking
Today’s digest spans talking avatars, 4D human reconstruction, and speech agents that anticipate endpoints and manage multi-party turns. It also includes expressive TTS with finer emotion control for more natural spoken output.

Qualitative comparison: same-scene condition. The reference video (cyan border, top row) provides identity context. All five methods generate from the same driving audio and scene image. produces the most faithful identity and natural motion. From Avatar V.
Talking Avatars & Lip Sync
Avatar V
Avatar V: Scaling Video-Reference Avatar Video Generation
Avatar V conditions on the full token sequence of a reference video to generate talking-avatar videos that capture both static identity features and dynamic behaviors like talking rhythm and expressions, delivering high-fidelity, natural, long-duration avatar videos beyond prior image-based methods.

ReFree-S2V
ReFree: Towards Realistic Co-Speech Video Generation via Reward-Free RL and Multilevel Speech Guidance
ReFree-S2V generates realistic talking head videos with accurate lip-sync and natural expressions using multi-level speech features and reward-free reinforcement learning to improve animation quality without manual rewards or labels.
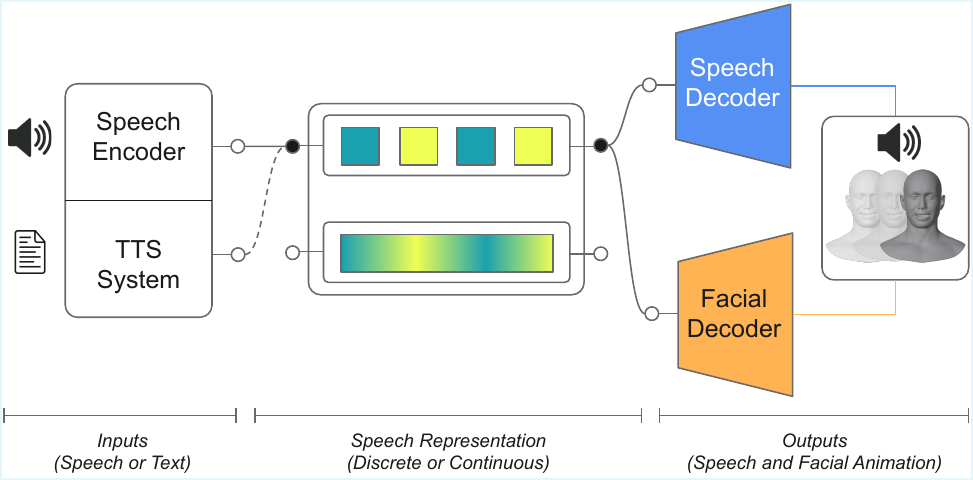
From Tokens to Faces
From Tokens to Faces: Investigating Discrete Speech Representations for 3D Facial Animation
This paper investigates how discrete and continuous speech representations impact 3D facial animation, showing phonetic encoding boosts facial motion accuracy. It introduces a shared discrete space enabling synchronized speech synthesis and face animation for a new audio-visual text-to-speech pipeline.
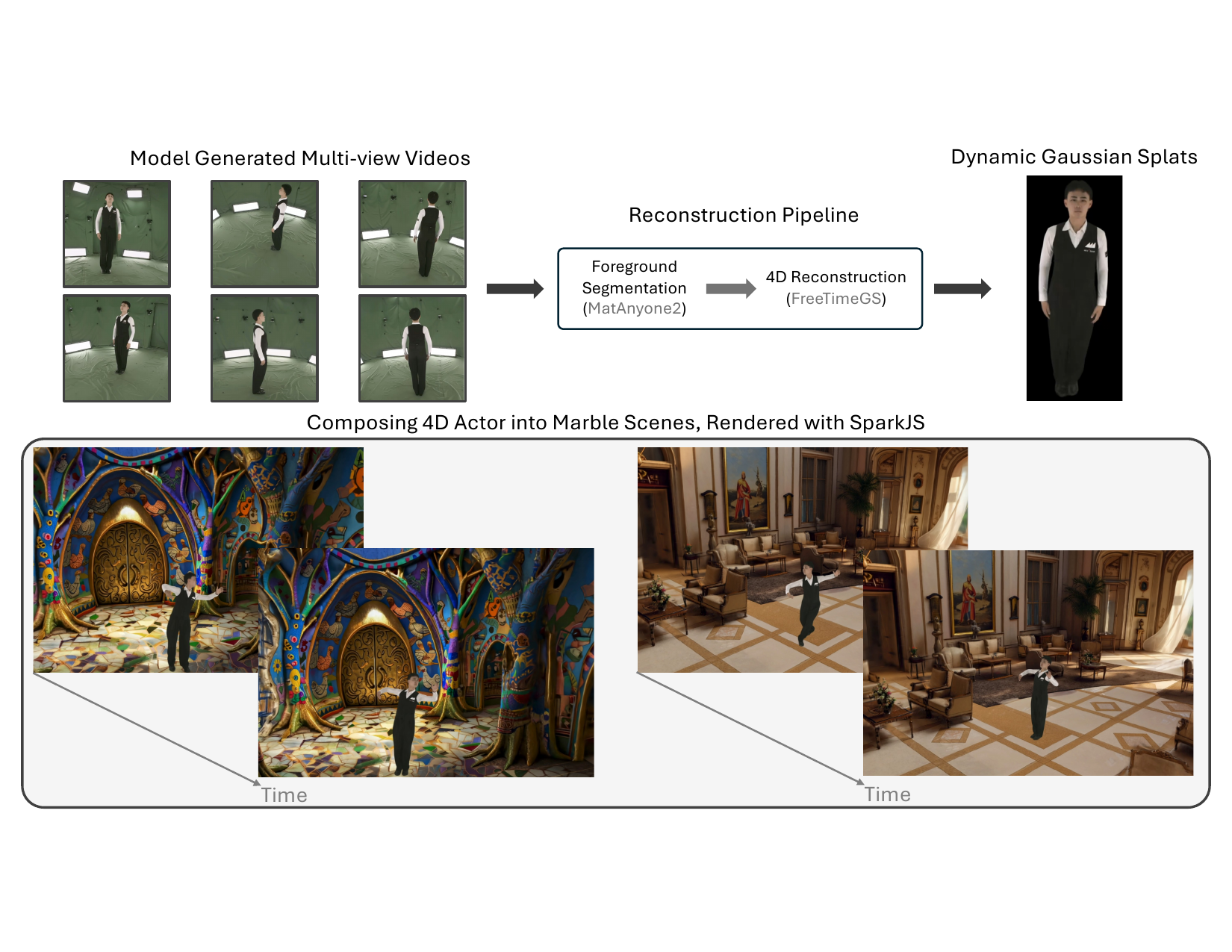
Digital Humans & 4D Reconstruction
SpeechLLMs & Voice Agents
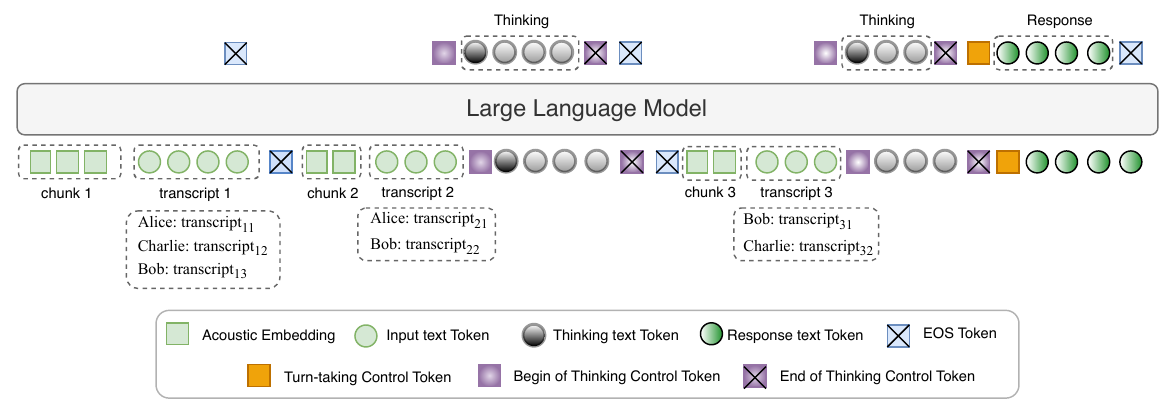
ModeratorLM
Adaptive Turn-Taking for Real-time Multi-Party Voice Agents
ModeratorLM is a role-conditioned voice agent for real-time multi-party conversations that adapts turn-taking based on explicitly assigned roles, improving precision and reducing interruptions compared to traditional methods by integrating role-specific reasoning and behavior.
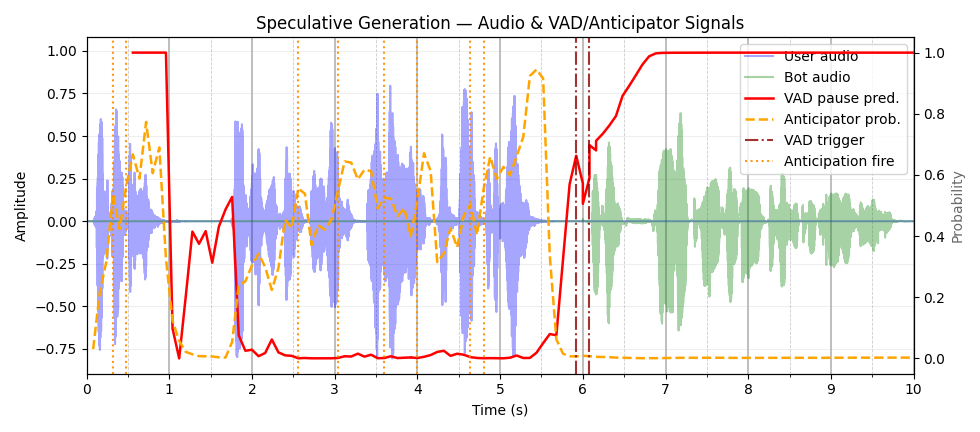
Endpoint Anticipation
Endpoint Anticipation for Low-Latency Spoken Dialogue
This paper proposes a proactive forecasting method for turn-endpoints in spoken dialogue, enabling downstream speech-to-speech pipelines to begin processing before the user finishes speaking. Unlike prior reactive systems, it reduces latency by speculative execution with controlled trade-offs on computation redundancy.

NaturalFlow
NaturalFlow: Reducing Disruptive Pauses for Natural Speech Flow in Simultaneous Speech-to-Speech Translation
NaturalFlow introduces a fluency-aware optimization for simultaneous speech-to-speech translation that balances low latency with natural speech flow by reducing disruptive pauses. It explicitly optimizes speech fluency to lower listener load without sacrificing translation quality.