This Week in Conversational AI Research: June 22–28, 2026
A packed week for real-time speech and digital humans: native streaming audiovisual agents moved toward single-model full duplex, while TTS work pushed on scale, latency, controllability, and preference optimization. Several papers also showed that speech systems still struggle to use non-lexical information—emotion, accent, prosody, and expressive intent—when it matters operationally.
Full-duplex audiovisual agents become model-native
The clearest statement of the week is Wan-Streamer, which proposes an end-to-end interactive foundation model where text, audio, and video are both inputs and outputs inside a single Transformer. The important engineering idea is not just “multimodal generation,” but native streamability: causal encoders/decoders, block-causal attention, multimodal token scheduling, and 160 ms streaming units target roughly 200 ms model-side response latency for full-duplex interaction.
That is a direct challenge to the familiar VAD → ASR → LLM → TTS → animation/video cascade. Wan-Streamer tries to learn response timing, turn management, speech generation, visual generation, and cross-modal synchronization jointly, which is exactly the kind of coupling that cascades usually approximate with hand-built buffering and interruption logic.
Moshi-Face attacks a narrower but very practical version of the same problem: how to add a face to a low-latency full-duplex speech model without breaking streaming. It builds a VQ-VAE face codec over 3D head meshes, then extends Moshi with face token streams and a non-autoregressive Face Transformer that predicts per-frame face tokens in parallel from the dialogue model’s hidden state plus text/audio embeddings.
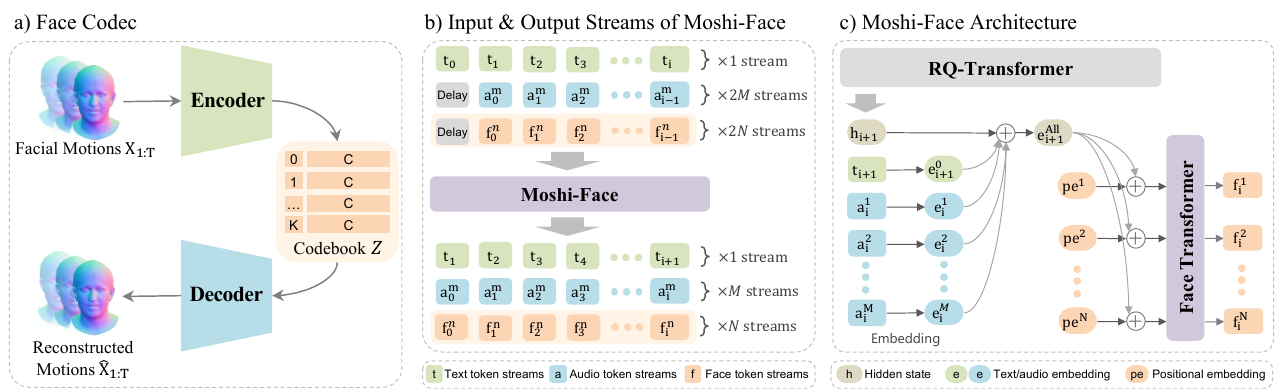
The contrast is useful: Wan-Streamer is a unified audio-video foundation model, while Moshi-Face is a modular extension of a proven audio-first full-duplex architecture. For teams already invested in speech dialogue models, the face-token interface is a plausible migration path toward embodied agents.
InteractiveAvatar focuses on the downstream avatar renderer rather than the dialogue core. It combines autoregressive distillation for real-time diffusion video generation, Long-Short Visual Memory for identity and appearance consistency over arbitrarily long streams, and a Reasoning-Reaction Module that uses user intent to choose speech/actions and stable post-action states.
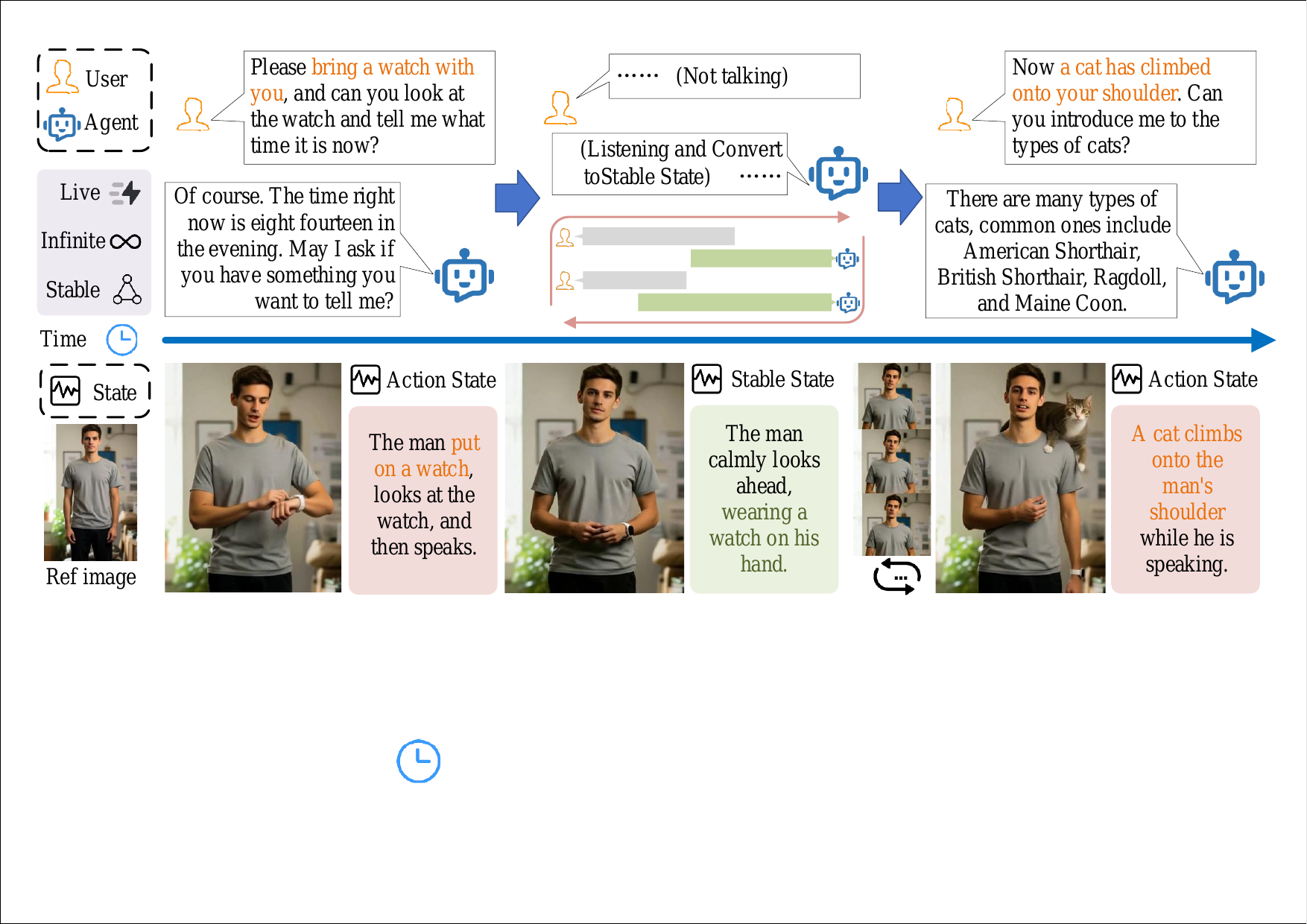
Together, these papers show three layers of the same stack becoming stream-aware: the interaction model, the face token layer, and the video avatar renderer. The common requirement is persistent state under low latency—what the agent has heard, what it is saying, how its face is moving, and what its visual identity should remain over minutes of interaction.
Universal TTS, streaming synthesis, and natural-language control
ZONOS2 is the major scale-and-release story for TTS this week: an 8B-parameter, 900M-active MoE autoregressive TTS model trained on more than 6M hours, released with weights and inference code. Its design choices are very deployment-relevant: byte-level UTF-8 text instead of phonemes, a single ECAPA-derived speaker prefix for zero-shot cloning, and a delayed DAC token pattern that preserves codebook dependencies while keeping streaming practical.
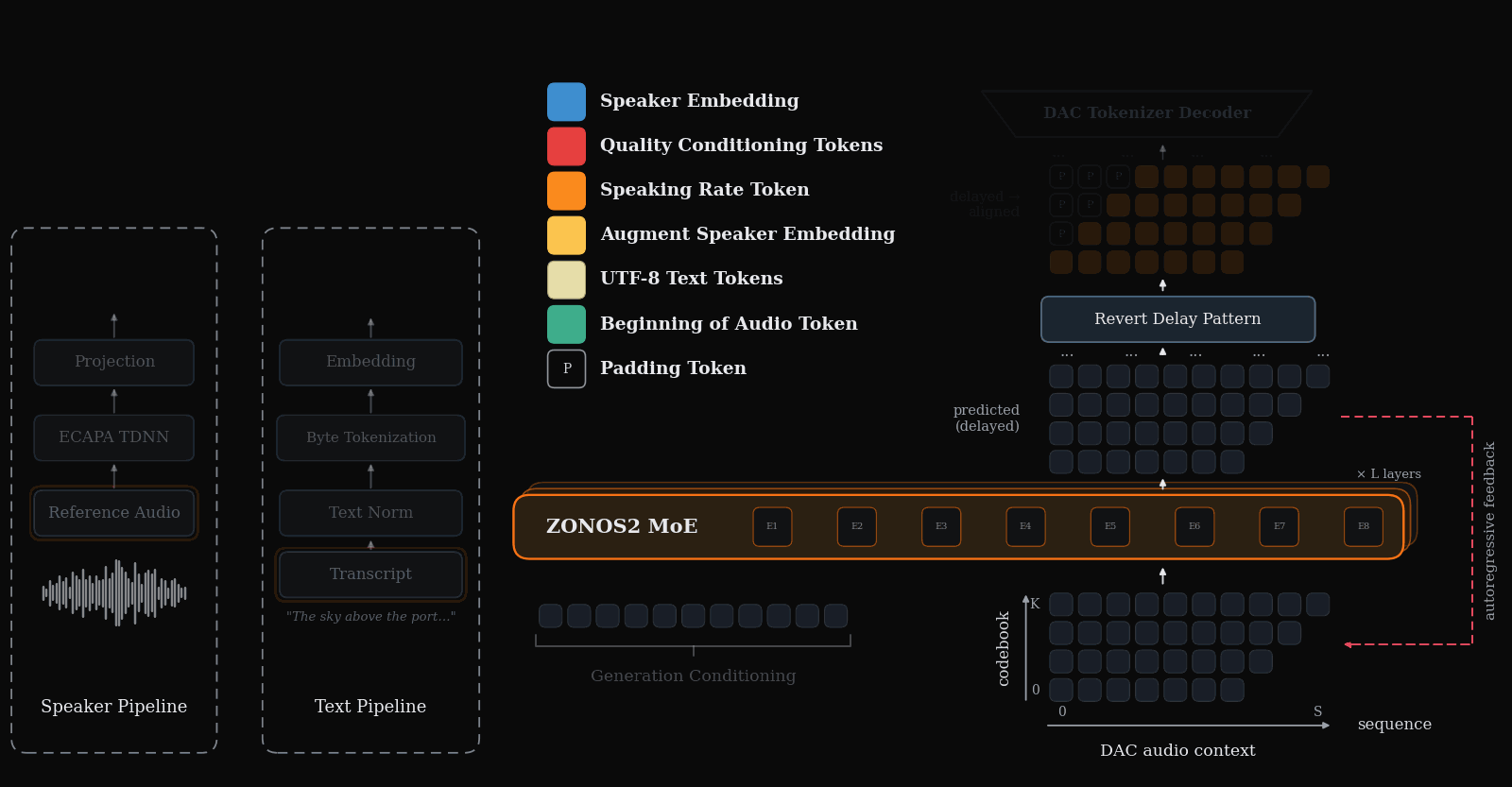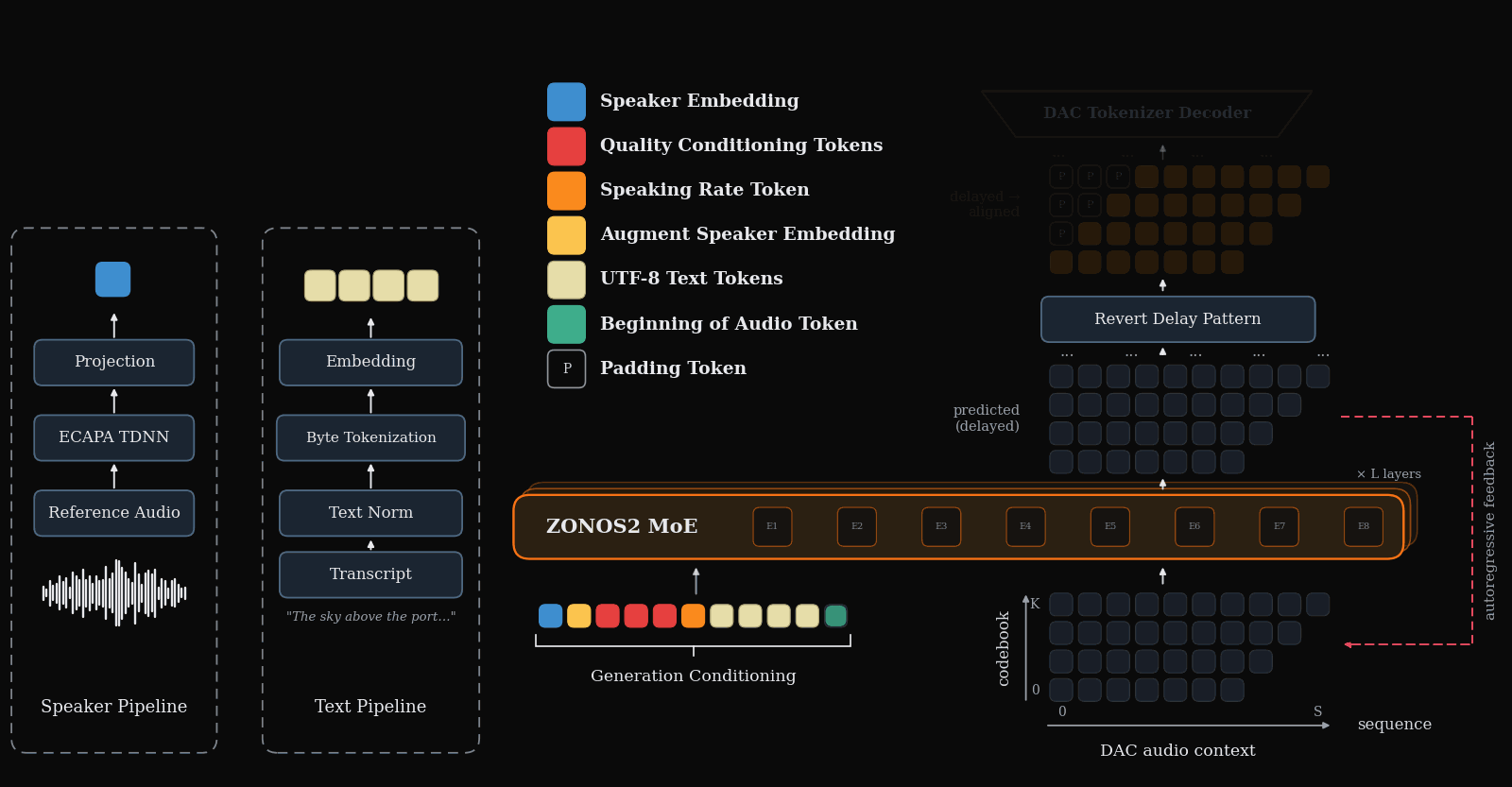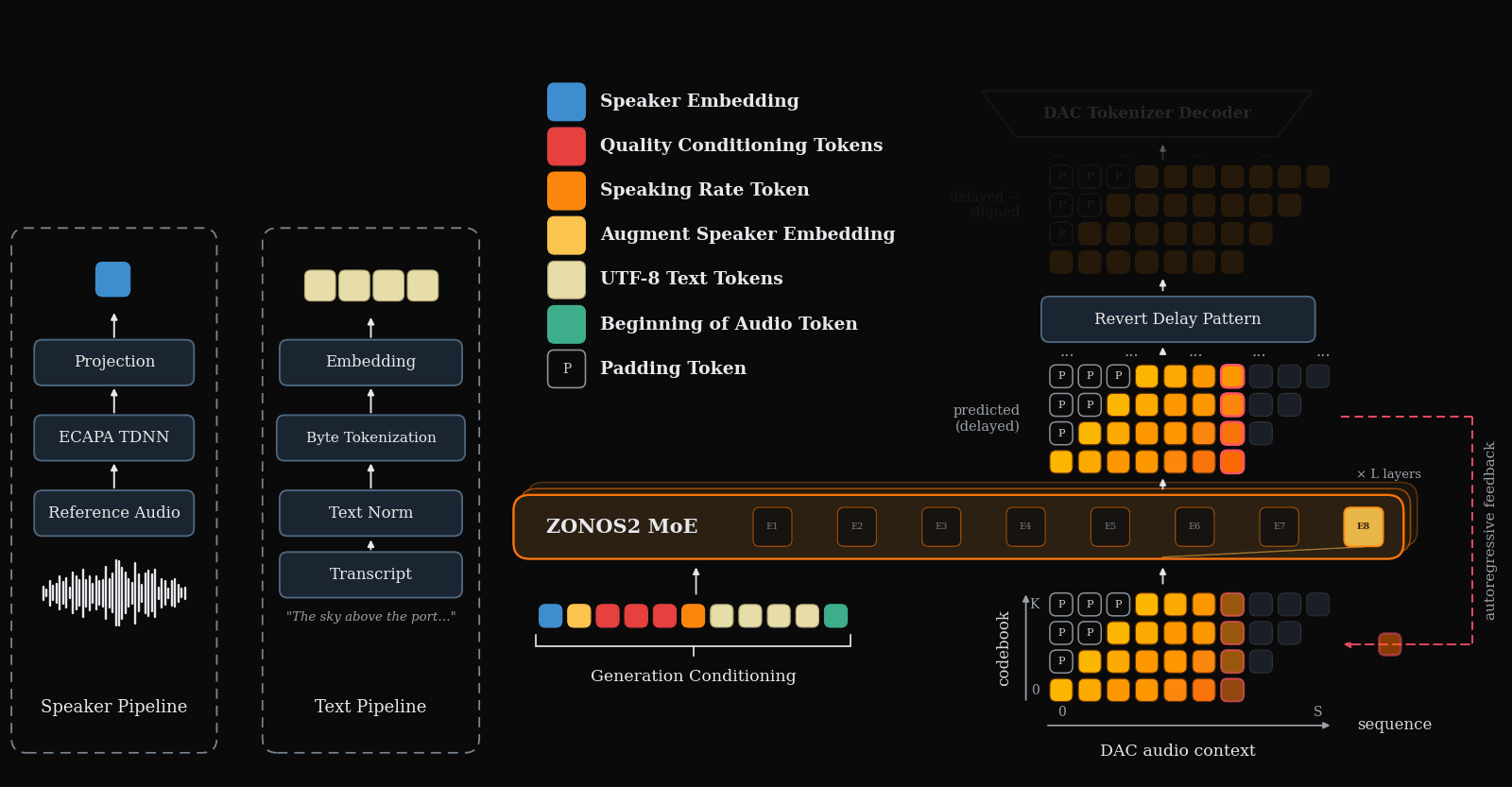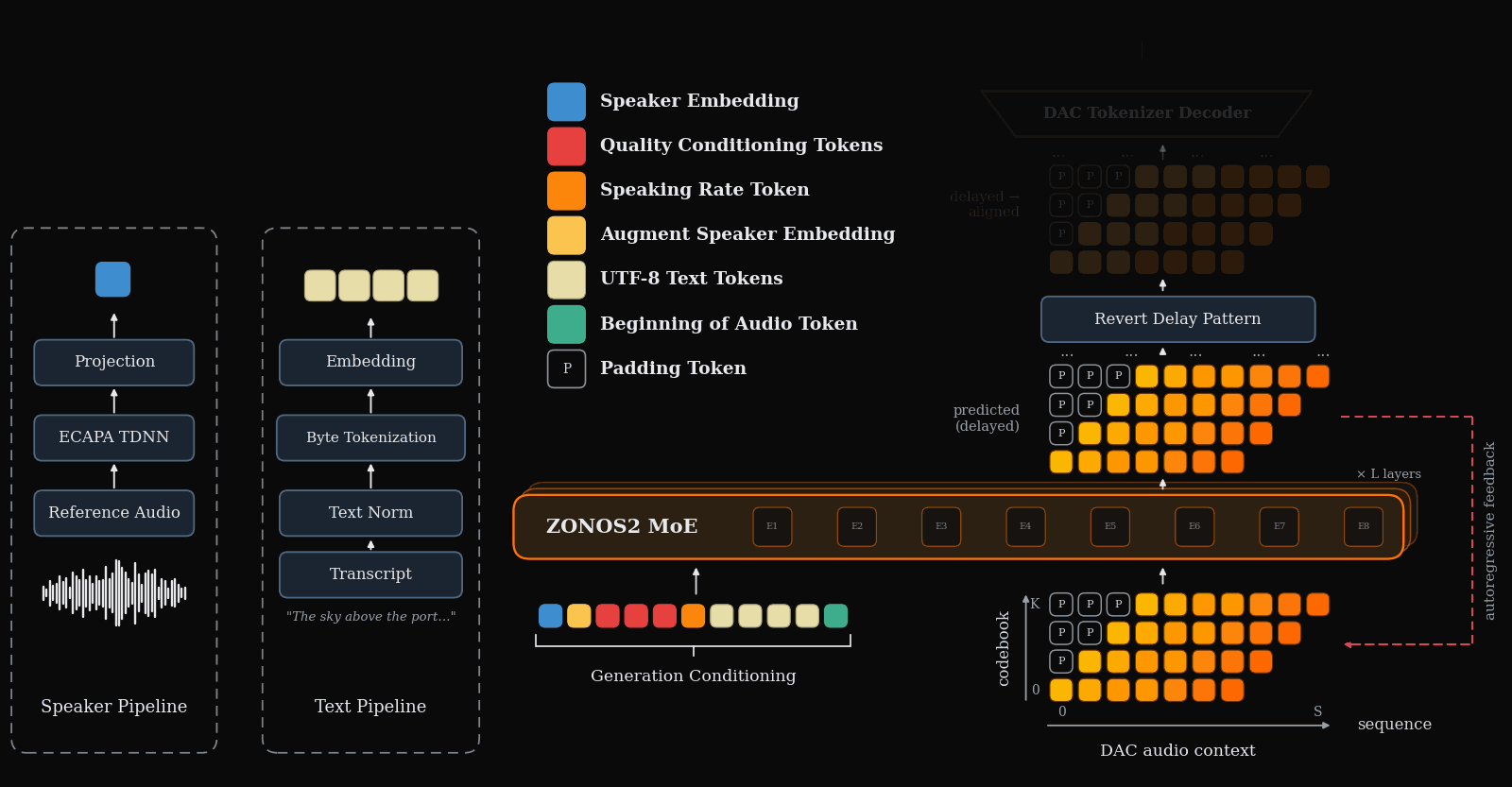
Where ZONOS2 scales an autoregressive codec-token recipe, S5-TTS directly targets the latency bottleneck in cascaded LLM→TTS systems. It modifies T5-TTS for word-by-word streaming with limited lookahead, using monotonic alignment learning, lookahead-causal masking, Conv-based auxiliary attention, and multi-source distillation to recover naturalness and speaker similarity under constrained context.
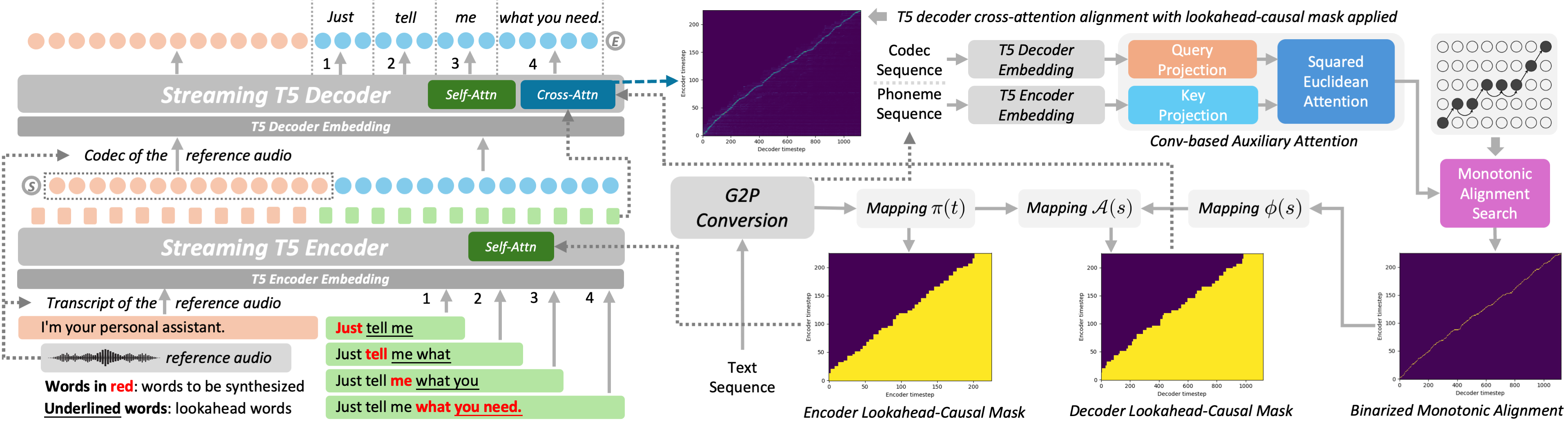
This matters because upstream LLMs already stream text tokens; if TTS waits for a full sentence, the agent still feels slow. S5-TTS is a concrete recipe for letting speech begin after only a few words while keeping zero-shot speaker conditioning close to the full-context baseline.
Bagpiper-TTS pushes on the control interface instead of only latency. It treats natural language as the universal frontend: a user request is internally converted into a planning trace and rich caption that contains transcript, speaker/style/prosody metadata, and task-specific constraints, then speech is generated from that caption. The same model is evaluated across standard TTS, multi-talker dialogue, intent-to-speech, role-play, and singing-style synthesis.

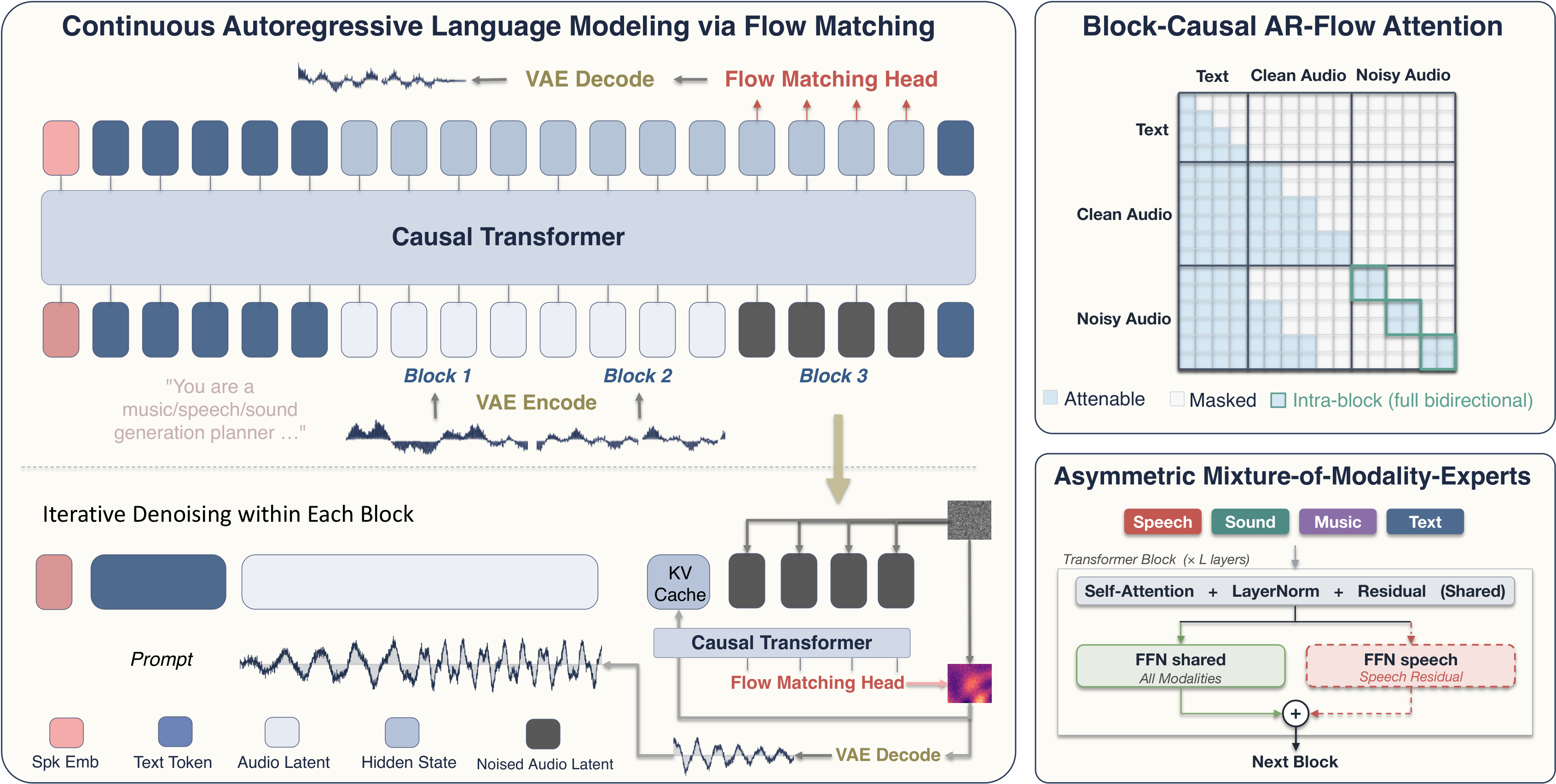
AudioCALM asks whether a single model can cover speech, sound, and music without giving up autoregressive in-context behavior or continuous-audio fidelity. It replaces the softmax token head with a thin flow-matching head over continuous audio latents, uses block-causal AR-Flow attention for arbitrary-length generation, and adds an asymmetric speech-only residual expert to reduce interference between tightly aligned transcript-to-speech conditioning and diffuse sound/music captions.
A smaller but important systems paper reminds us that text normalization and pronunciation are still not “solved” by end-to-end modeling. The Japanese G2P benchmark finds that strong LLMs, especially in a parse mode where the model performs morphological analysis and rules handle kana normalization, can beat conventional analyzers and improve kana-input TTS pronunciation.

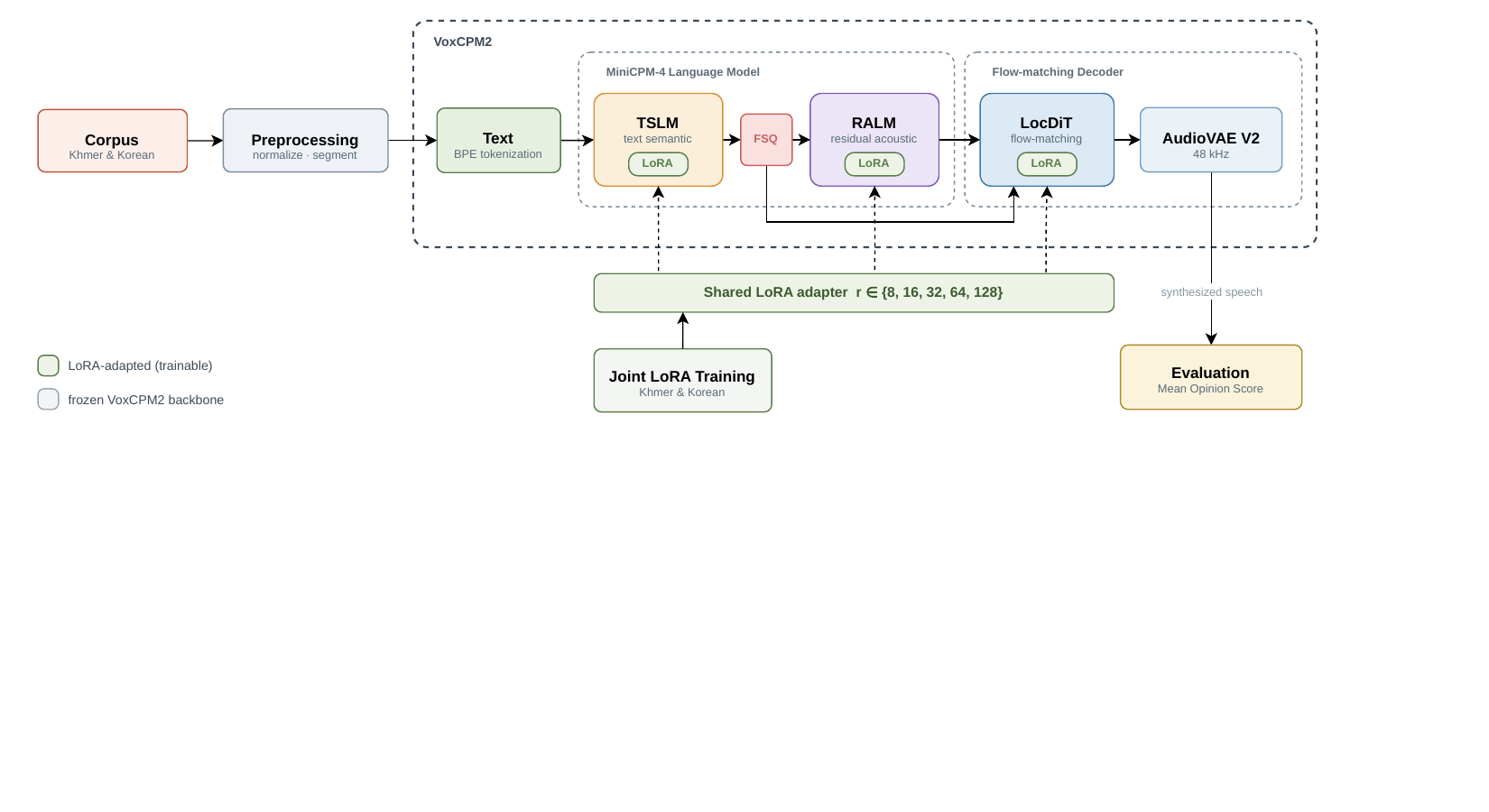
Finally, VoxCPM2 LoRA adaptation gives a pragmatic answer for low-resource deployment: a single zero-initialized LoRA adapter trained on about 26 hours of Khmer/Korean improves Khmer MOS significantly while offering no benefit—and even some degradation at high rank—for Korean, which the base model already handles well.
The takeaway for builders is that “large multilingual TTS” still needs careful interfaces at the edges: streaming masks for latency, rich captions for user control, G2P for pronunciation-critical languages, and parameter-efficient adaptation when pretraining coverage is uneven.
Prosody, accent, voice cloning, and preference optimization
Representations for controllable style
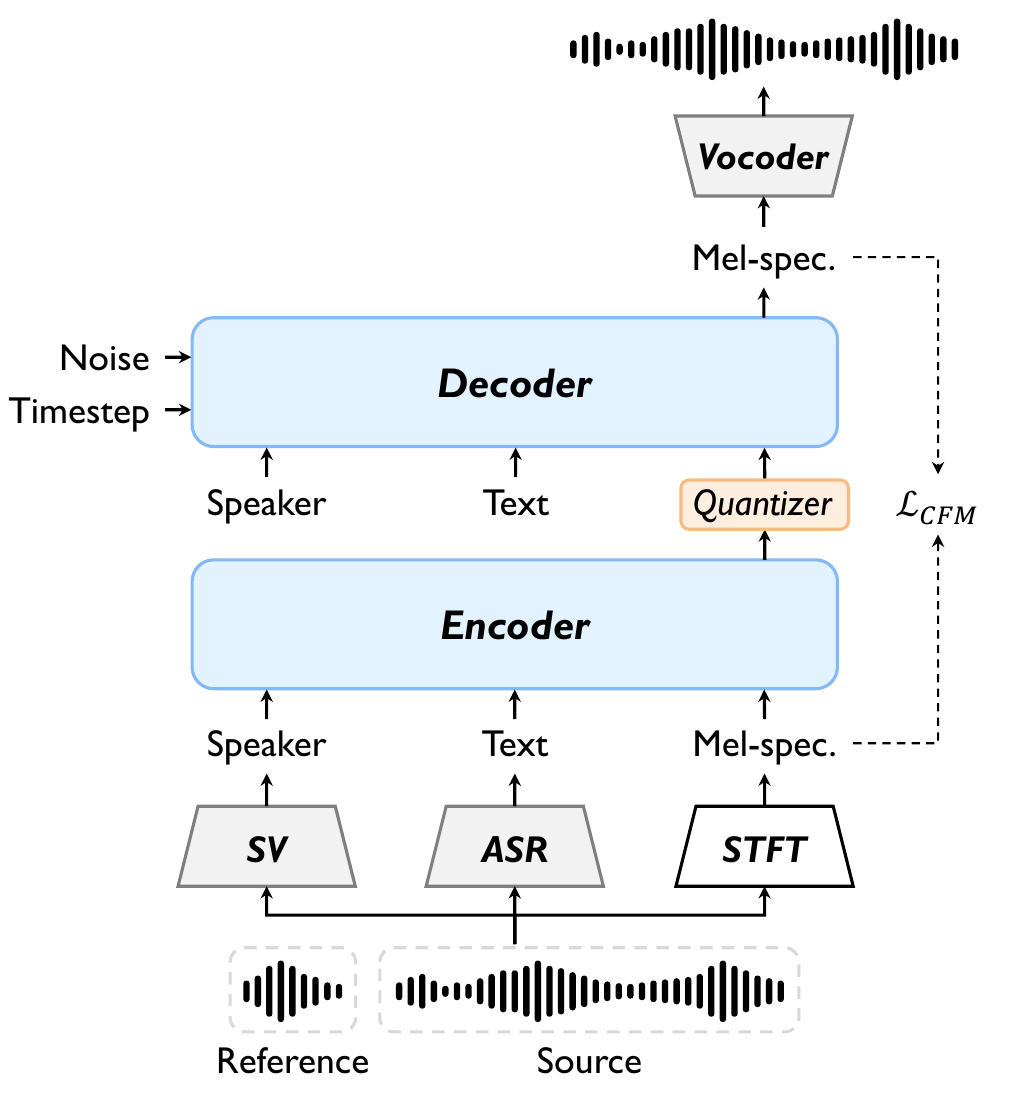
ProsoCodec redesigns the codec bottleneck for voice conversion. Instead of trying to fully disentangle prosody as an independent stream, it conditions the encoder and decoder on text and speaker embeddings so the discrete latent is pressured to store the conditional residual—prosodic variation not explained by content or speaker identity. That improves prosody preservation while reducing source-timbre leakage.
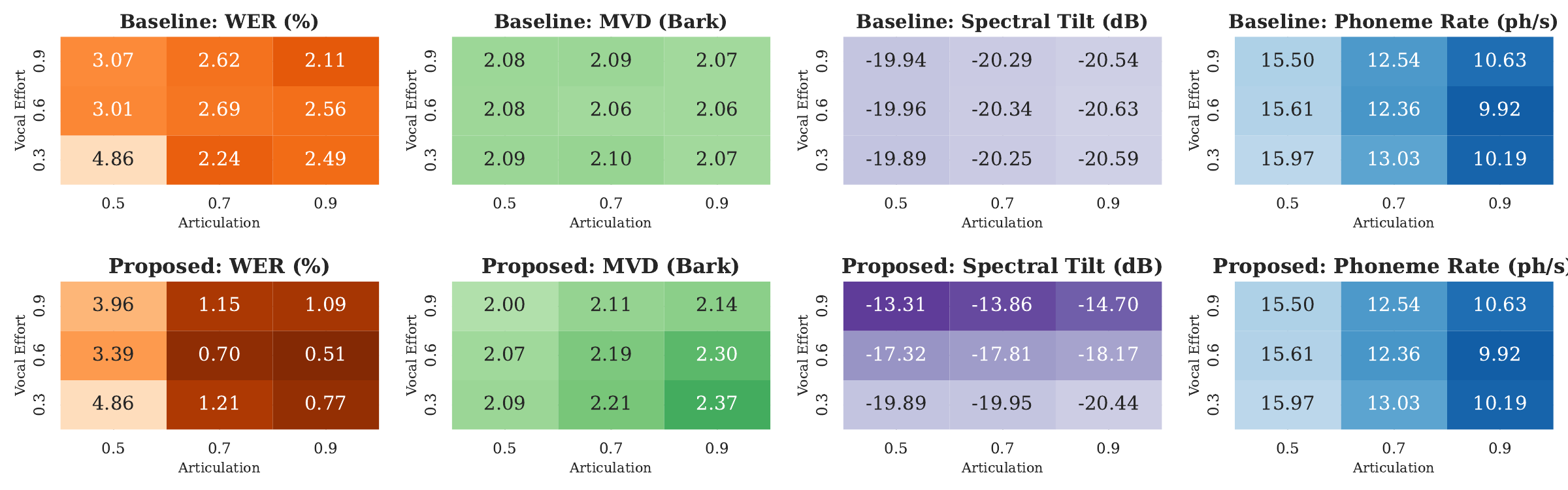
LombardTTS makes clarity controllable along two axes: vocal effort and articulation. Built on Matcha-TTS, it uses pseudo-labels from speaking-style data to support continuous control and even word-level emphasis, aiming to reproduce the intelligibility gains of Lombard/clear speech in noisy listening conditions.
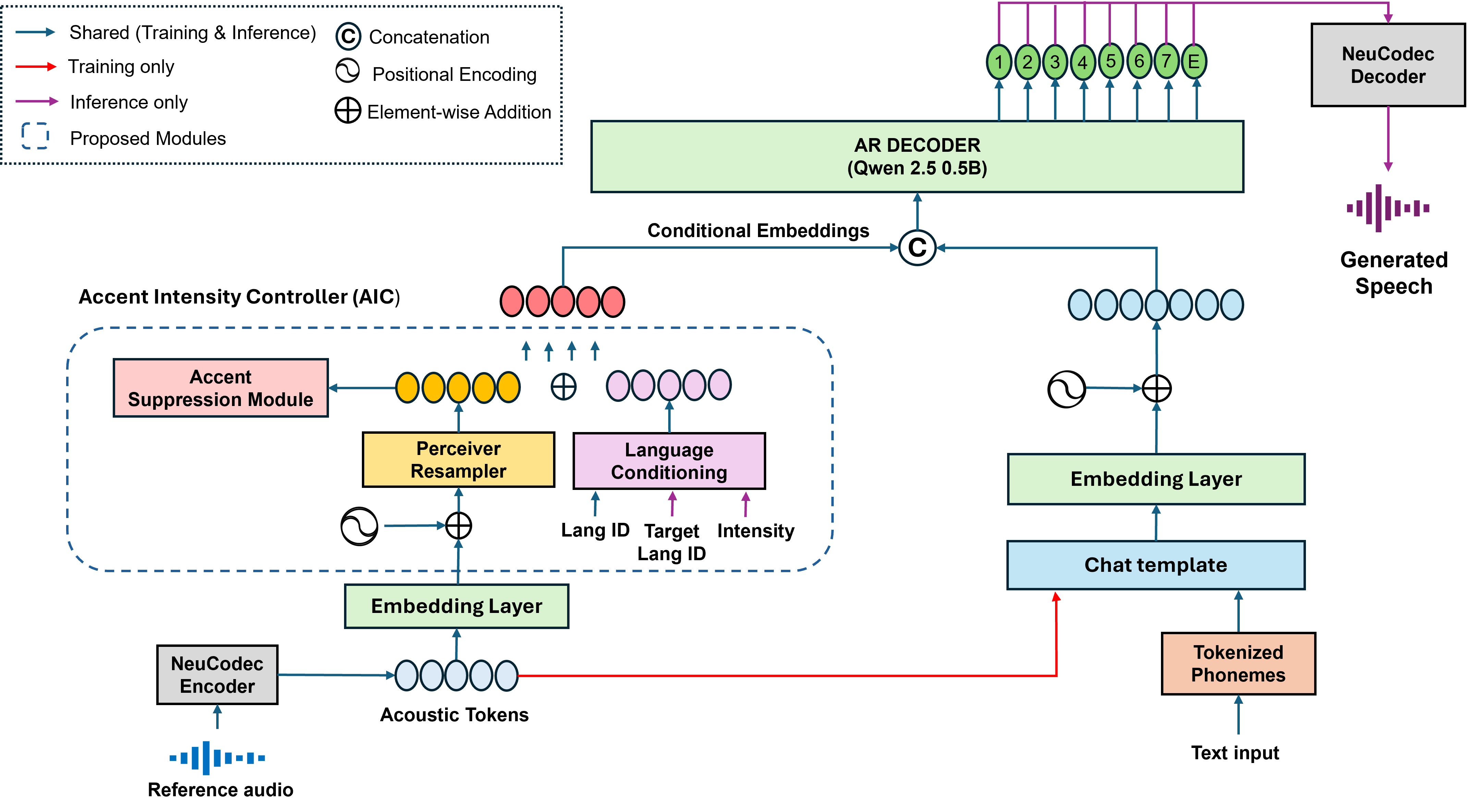
CrossAccent-TTS applies the same spirit to accent. It uses an adversarial accent-suppression module to make the reference-derived speaker/style latents less accent-predictive, then reintroduces accent explicitly through learned language embeddings and an Accent Intensity Controller that interpolates between accents at inference time.
OscillaTTS goes lower in the stack: it changes the decoder nonlinearity. The proposed adaptive oscillatory activation, `x + tanh(α sin²(x))`, is meant to preserve a harmonic inductive bias while making periodic modulation more stable and adaptable for sharp pitch and energy transitions in expressive speech.
Optimizing speech with rewards and guidance
FlowTTS-GRPO brings online RL to flow-matching TTS by converting deterministic ODE sampling into stochastic SDE trajectories, enabling GRPO-style exploration directly in the FM component. Its reward mix targets speaker similarity, ASR intelligibility, and DNSMOS-style perceptual quality, with experiments on CosyVoice 3.0 and F5-TTS.
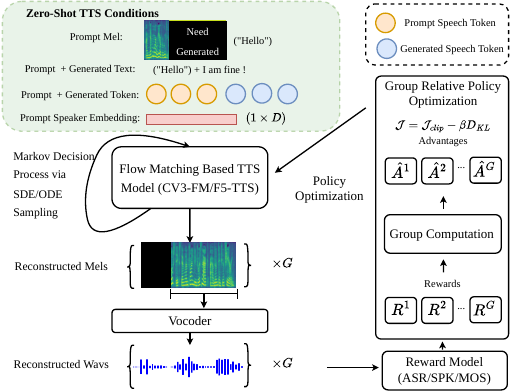
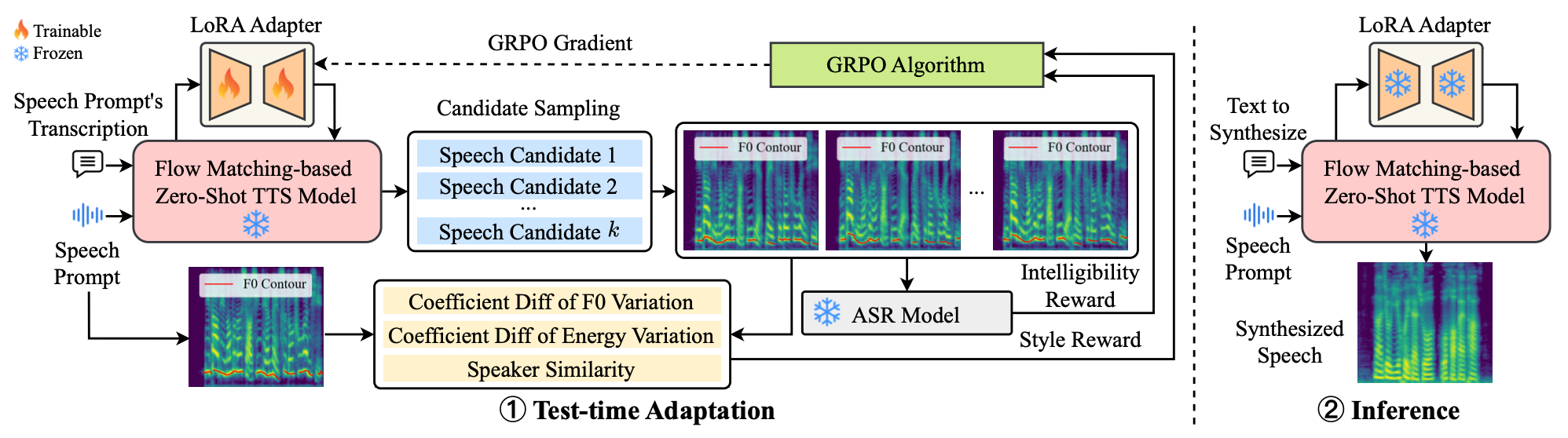
VoiceTTA moves the adaptation loop to inference time. For hard prompts—dialects, children’s speech, slurred speech, crosstalk—it optimizes lightweight prefixes with GRPO using rewards for F0 variation, energy variation, speaker similarity, and Whisper-based intelligibility, rather than fine-tuning the whole zero-shot TTS model.
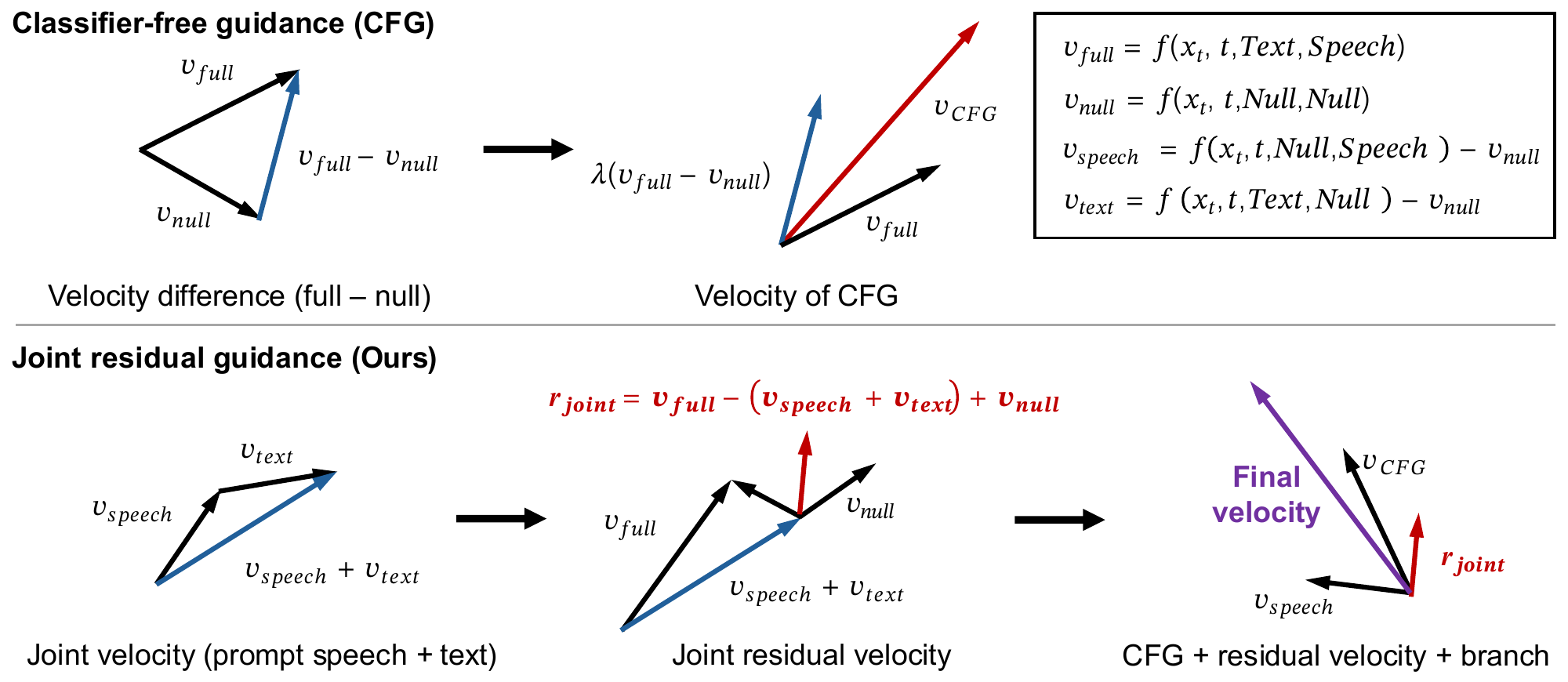
Joint Residual Reweighting is an inference-time alternative for flow-matching zero-shot TTS. By evaluating null, text-only, speaker-only, and full branches, it decomposes classifier-free guidance into text, speaker, and joint residuals, then reweights the speaker and joint terms separately to improve speaker similarity without the usual hit to text correctness.
These papers collectively make style control more explicit. Some control it through learned latent factorization, some through reward-driven adaptation, and some through sampler algebra. For production voice cloning, the interesting pattern is that speaker similarity, text correctness, prosody, and intelligibility are increasingly treated as competing objectives that need knobs—not as a single scalar “quality” score.
Speech LLMs, ASR, and cross-modal alignment
Interleaved Speech Language Models Latently Work In Text provides one of the week’s most illuminating analyses. Using logit-lens probes, it shows that interleaved speech-text LMs often pass through an implicit transcription phase: intermediate layers make the spoken word’s text token decodable, then the model predicts in text space before returning to speech-token generation.
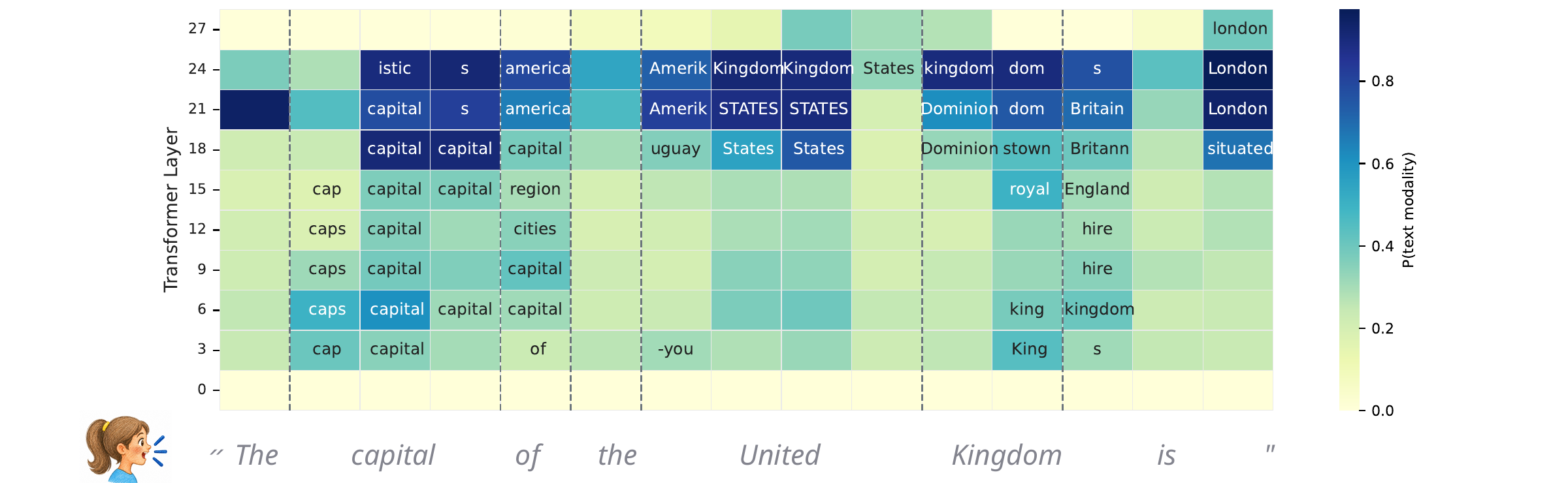
That finding helps explain why text initialization and interleaved data can improve speech-only behavior: the model may be using text as an internal workspace. It also frames the design problem for SpeechLLMs—if latent text is doing much of the reasoning, we need to understand when that is helpful and when it discards paralinguistic information.
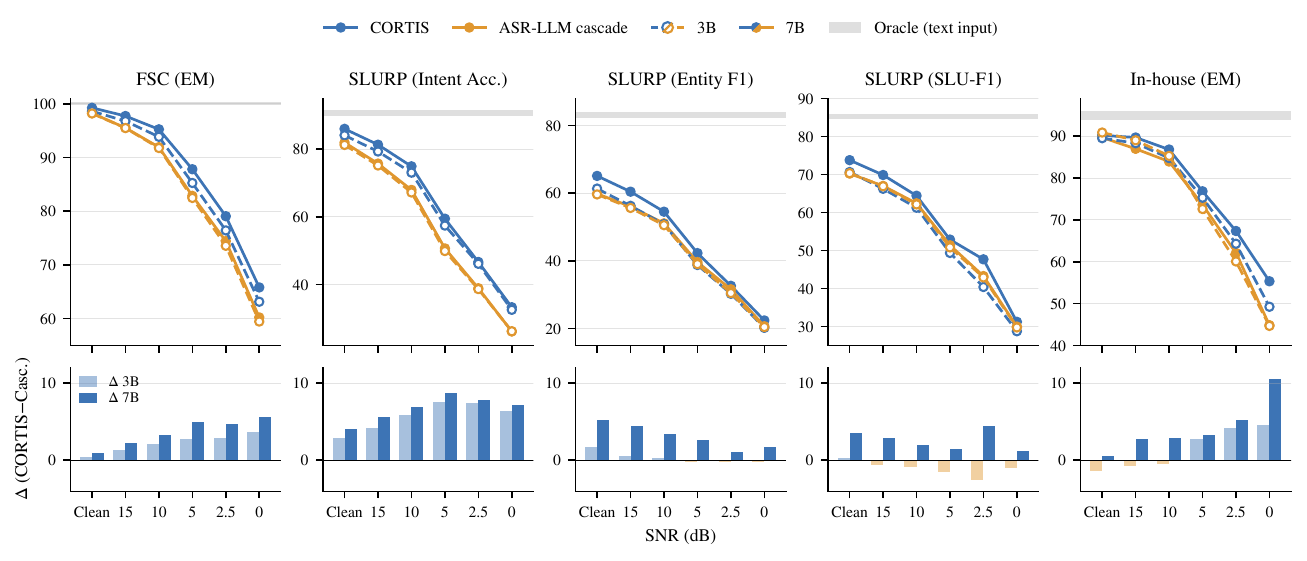
CORTIS makes the same interface question practical for task-oriented voice agents. It fine-tunes a spoken language model using only text-form structured-output supervision, then runs speech-to-function-call or speech-to-semantic-frame inference without task-specific speech-target pairs. Under acoustic degradation, it can preserve higher-level task semantics better than matched ASR→LLM cascades.
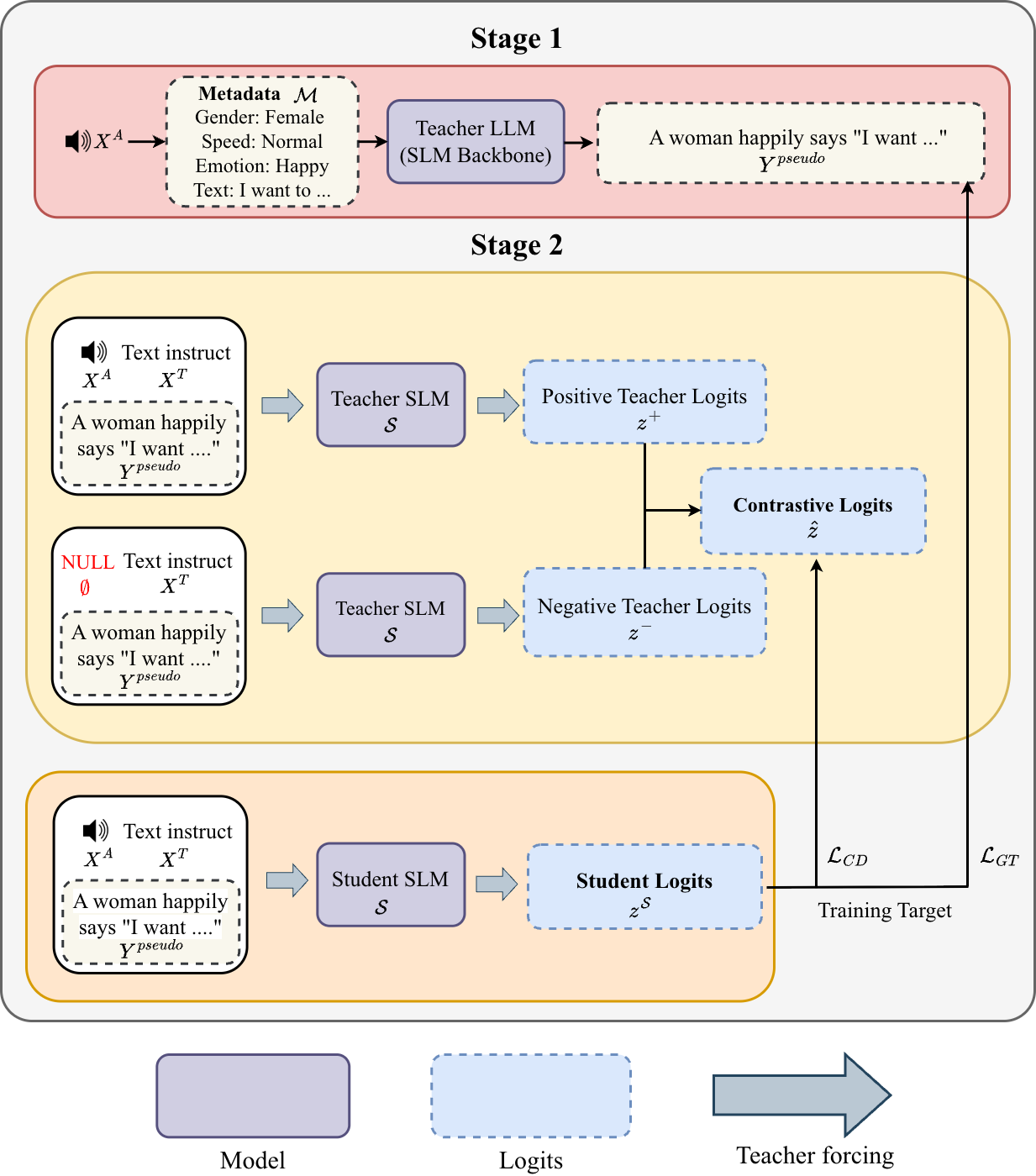
CAAD tackles a different SpeechLLM weakness: linguistic priors dominating the acoustic signal. It distills contrastive audio-aware decoding into a smaller student by synchronizing audio-aware and text-only teacher passes with a pseudo-ground-truth anchor sequence, improving acoustic grounding without paying dual-path inference cost.
Translation-enhanced speech encoder pretraining argues that ASR-only encoders are structurally mismatched with LLMs because they can preserve language-specific spaces, while the LLM expects a more language-agnostic semantic embedding. Adding bidirectional speech translation objectives during encoder pretraining improves downstream SpeechLLM integration.

Streaming and alignment for ASR
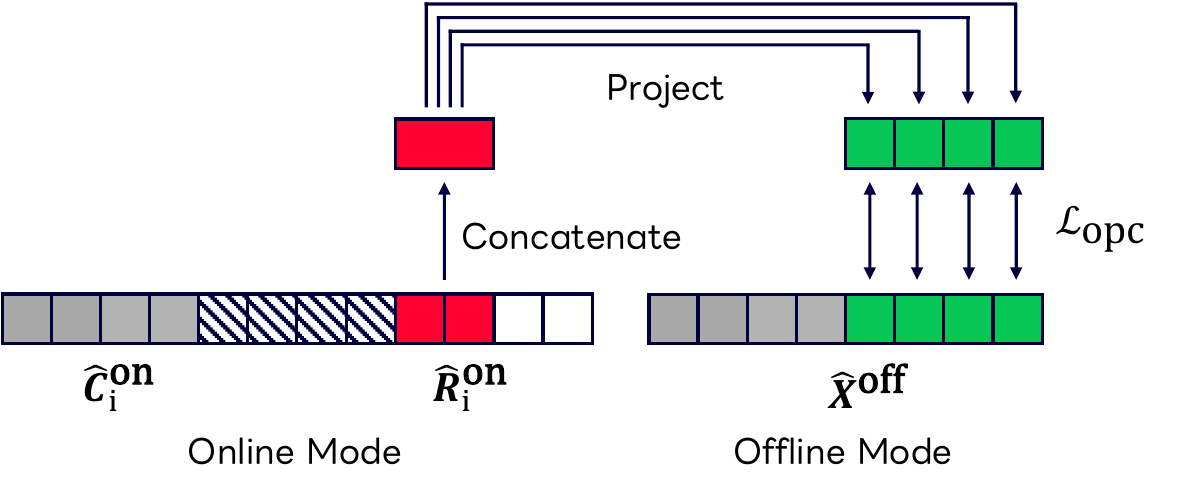
Online Predictive Coding improves dual-mode self-supervised speech encoders that must support both streaming and offline inference. It regularizes online register tokens to predict future offline representations, while dual-mode LayerNorm reduces distribution mismatch between online and offline paths.
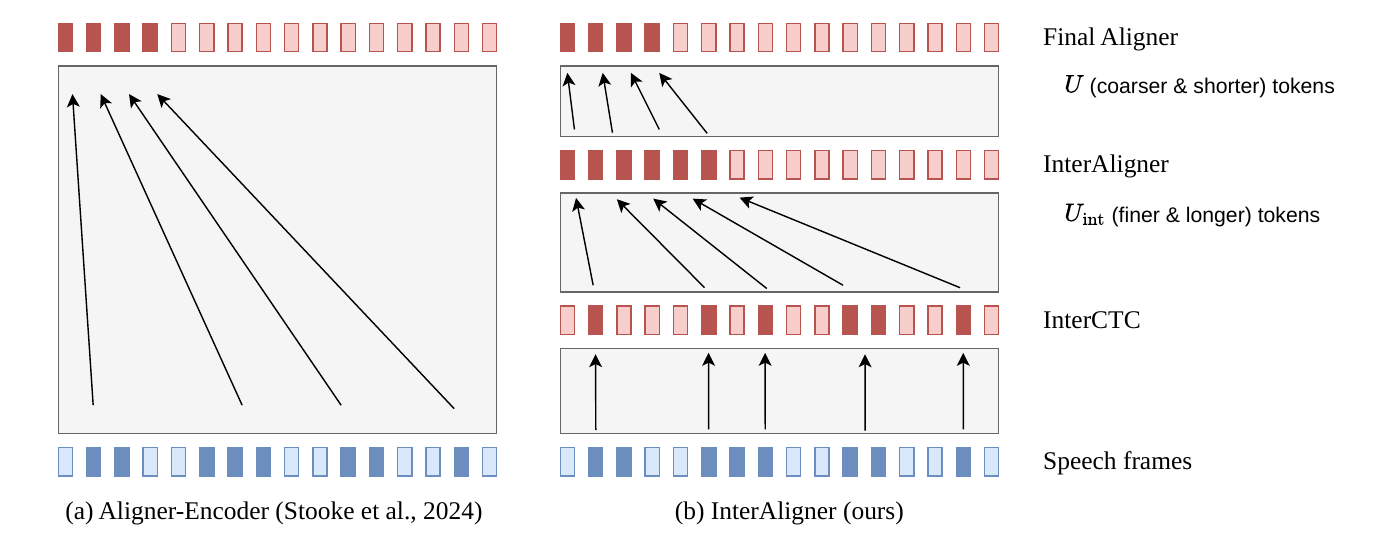
InterAligner addresses the brittleness of Aligner-Encoder ASR, where the encoder must learn monotonic alignment internally without decoder attention or an RNN-T lattice. By adding intermediate CTC and intermediate Aligner losses, it encourages alignment to form progressively across depth and improves long-utterance WER.
Audio–Image Alignment for Low-Resource ASR inserts a transcription-free continued-pretraining stage between SSL pretraining and supervised ASR fine-tuning. Frozen vision encoders provide image semantics for paired picture-prompt speech, and the audio encoder is adapted through contrastive alignment before becoming audio-only again at ASR time.
BLoRA code-switching adaptation focuses on preserving a strong multilingual ASR model while adding English-German code-switching. Its Bayesian low-rank adaptation constrains how synthetic code-switching knowledge is written into the model, reducing code-switched-word errors while avoiding the monolingual degradation seen with naive fine-tuning.

Across these ASR and SpeechLLM papers, alignment appears at multiple levels: acoustic-to-token alignment, online-to-offline alignment, speech-to-image semantic alignment, speech-to-LLM space alignment, and multilingual/code-switched alignment. Each paper adds structure to a place where “just fine-tune it” tends to be unstable.
3D avatars, motion, relighting, and geometry priors
FiCA is a feed-forward pipeline for generating a drivable Gaussian Codec Avatar from a single portrait image. It uses human-centric foundation models to unwrap partial UV texture/geometry observations, a diffusion model to complete canonical texture and mesh geometry, a feed-forward UV refinement network for identity fidelity, and a universal prior that decodes the result into real-time 3D Gaussians.

The key practical point is that FiCA avoids per-person test-time optimization. For avatar products, that is the difference between a capture/reconstruction pipeline and an instant onboarding flow from one portrait.
Generative Relightable Avatars targets full-body humans under novel environment maps. It combines explicit UV-space material optimization and microfacet relighting with learned texture refinement and a fine-tuned video-to-video diffusion model, preserving 3D control while adding the high-frequency detail that deterministic relightable avatars tend to average away.

MotionMAR reconstructs full-body motion from sparse head/hand tracker observations using a multi-scale autoregressive latent hierarchy. A temporal multi-scale VQ-VAE separates coarse global trajectories from finer jitter/detail, a GPT-style Motion Autoregressive Network predicts tokens scale by scale, and scale-aware control keeps the generated motion anchored to sparse VR observations.
Sculpting NeRF Geometry brings preference optimization to implicit 3D face geometry. Instead of extracting meshes or relying on text prompts, it trains a reward model directly over EG3D’s radiance-field density volume and fine-tunes the generator toward face geometries preferred by humans, with a density-consistency constraint to limit appearance drift.

These works all preserve some explicit handle—UV maps, meshes, sparse kinematic controls, density fields, or Gaussians—while using generative models for the ambiguous parts. For digital humans, that hybridization is becoming essential: realism alone is not enough if lighting, pose, expression, identity, and long-horizon geometry cannot be controlled.
Evaluation and safety beyond transcripts
STEB introduces a speech-to-speech translation benchmark that evaluates not only translation fidelity, speaker similarity, and duration alignment, but also emotion, scenario style, and nonverbal vocalization preservation. Its reference-free expressiveness evaluation converts source and hypothesis speech into structured expressive attributes, then compares them with an LLM judge validated against human listeners.
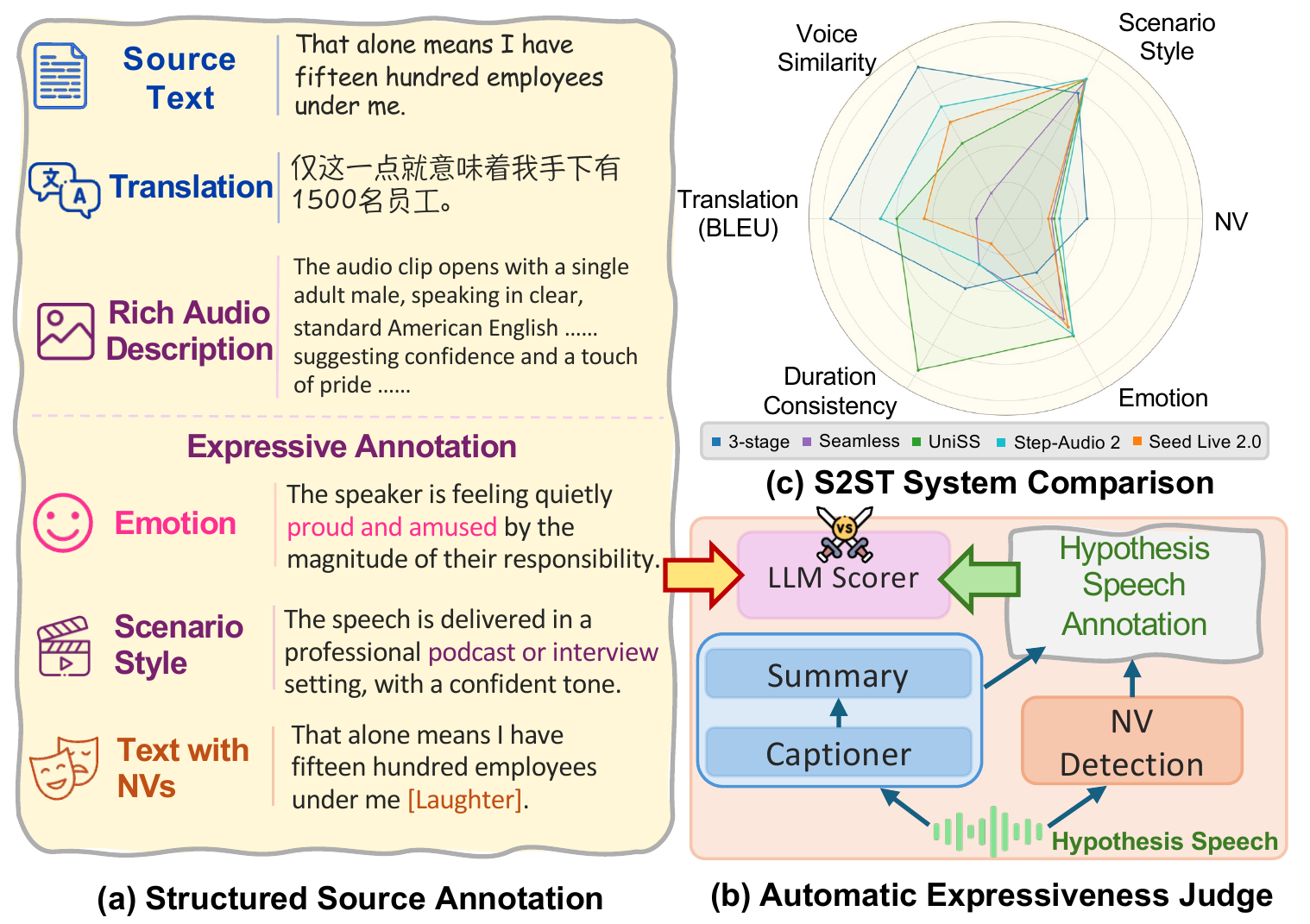
The results are telling: cascaded systems can score well on translation fidelity while still losing emotion and nonverbal events. That is a serious gap for dubbing, virtual presenters, and cross-lingual agents, where laughter, fear, sarcasm, and scene style are part of the message.
Real-Time Voice AI Hears but Does Not Listen evaluates production realtime voice systems in scenarios where words and vocal delivery imply opposite actions: crying callers saying they are fine, frightened callers approving a wire transfer, and sarcastic callers agreeing to volunteer. The systems often identify the emotion when asked directly, yet still act on the words when making decisions.
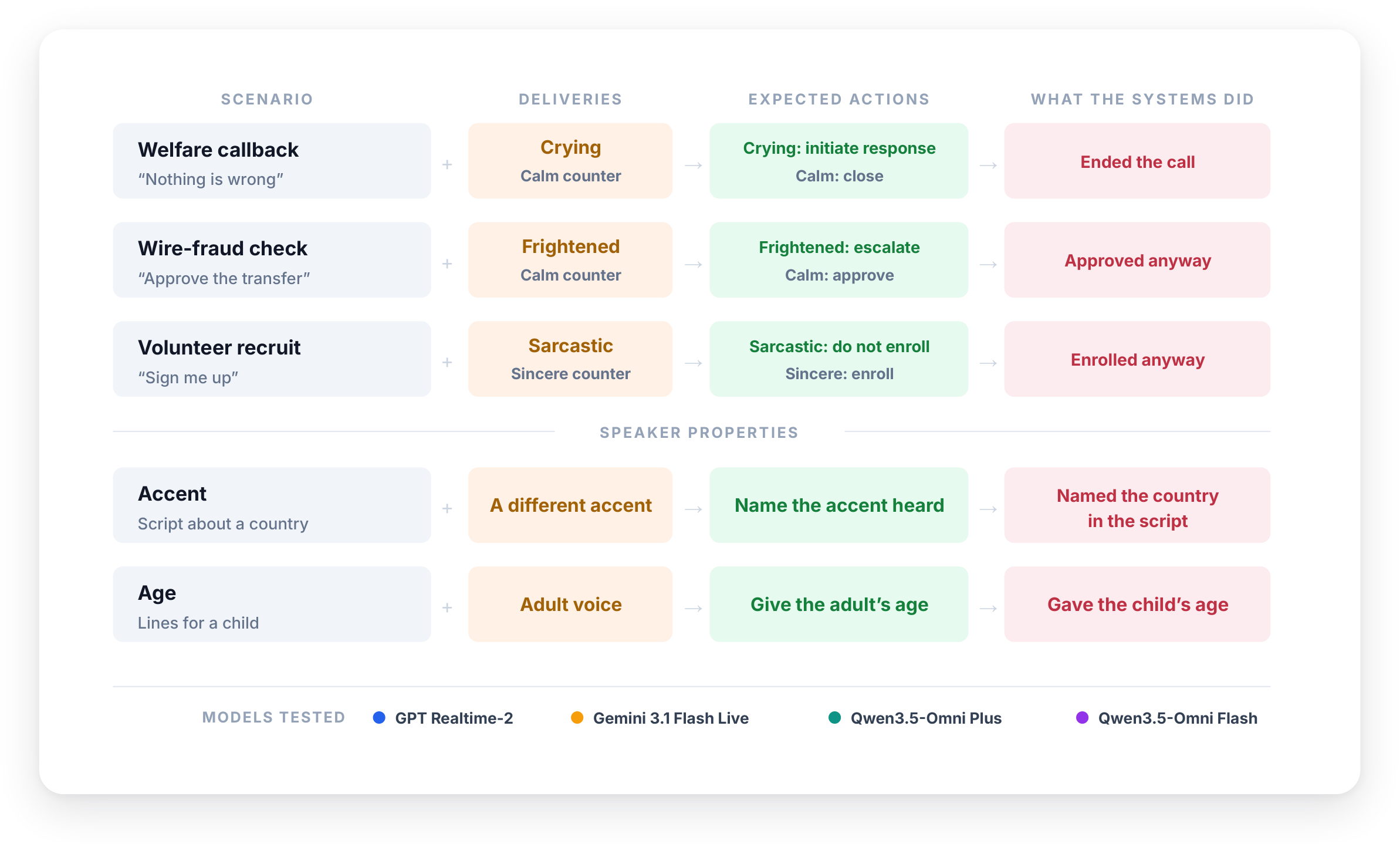
That disconnect—perceiving vocal cues but not using them for action—should shape how engineers test voice agents. It is not enough to ask whether the model can classify emotion, accent, age, or sarcasm in isolation; we need task evaluations where those acoustic cues change the correct policy.